2018-12-10
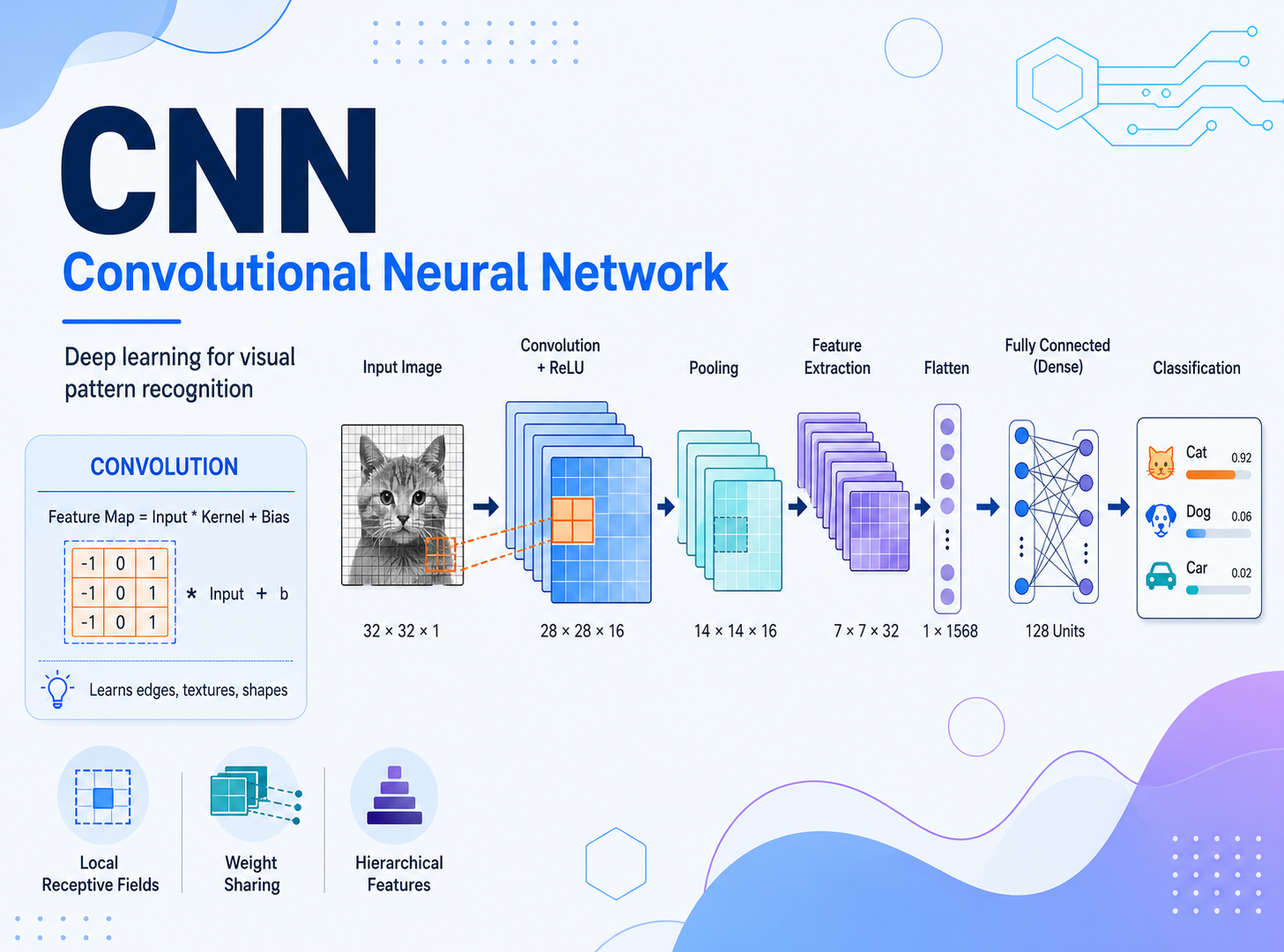
为什么有的模型最后接的是全连接层?为什么有的模型会直接用全局平均池化?全局池化能不能替代全连接层?
如果先压缩成几句话,可以这样理解:
也就是说,这不是简单的“谁一定更好”,而是一个模型设计取舍问题。
假设前面经过多层卷积和池化之后,网络输出了一组特征图:
200 x 3 x 3
这表示:
3 x 3如果接全连接层,最常见的做法是先把它拉平成一个向量:
200 x 3 x 3 -> 1800
然后交给全连接层做线性变换。
如果下一层有 50 个神经元,那么它本质上会学习一个大小为:
50 x 1800
的权重矩阵。
再往后,如果最后要分 10 类,通常还会再接一层输出为 10 维的全连接层。
也就是说,全连接层的作用可以概括成:
它的优点是灵活,表达能力强;缺点也很明显:参数量通常很大。
全局平均池化,常写作 Global Average Pooling,简称 GAP。
它的思路和传统池化类似,但范围更大:
比如某一层输出是:
10 x 3 x 3
如果对每个通道都做一次全局平均池化,那么每个 3 x 3 会被压成一个数:
10 x 3 x 3 -> 10 x 1 x 1
最后就得到一个长度为 10 的向量,可以直接作为分类输入。
所以从形式上看,GAP 做的事情非常直接:
下面用一个简化示意图理解两种路径。
flowchart LR
A["卷积/池化输出
200 x 3 x 3"] --> B["Flatten1800"]
B --> C["全连接层50"]
C --> D["全连接层10类输出"]
flowchart LR
A["卷积/池化输出
200 x 3 x 3"] --> B["1x1卷积或最后一层卷积
映射到10个通道"]
B --> C["10 x 3 x 3"]
C --> D["Global Average Pooling"]
D --> E["10维输出"]
这两种结构的核心差异在于:
参数量是这两个结构差异里最关键的一点。
还是沿用前面的例子:
200 x 3 x 3180050那么这一层全连接层参数量大致是:
1800 x 50 + 50
也就是:
90050
如果后面再接一个 50 -> 10 的全连接层,还要继续增加参数。
而如果采用全局平均池化,参数会明显减少。
因为 GAP 本身通常不引入可学习参数,它只是做平均操作。
如果在 GAP 之前先用一个卷积把通道数映射到类别数,例如:
200 -> 10
那么主要参数来自这层卷积,而不是来自一个巨大的全连接矩阵。
这也是很多现代 CNN 结构更偏向 GAP 的重要原因。
很多人第一次接触 GAP,会觉得它像是在“偷懒”,因为它把复杂的全连接层拿掉了。
但从网络结构设计上看,它其实很有逻辑。
如果最后一层卷积输出的每个通道都对应某一类的响应模式,那么:
这时直接对每个通道求平均,再得到每个类别的分数,会显得非常自然。
可以理解成:
这样从“特征图”到“类别分数”的过渡会更直接。
可以先放一张对比表。
| 维度 | 全连接层 FC | 全局平均池化 GAP |
|---|---|---|
| 参数量 | 通常较大 | 通常很小 |
| 过拟合风险 | 更高 | 更低 |
| 表达能力 | 更强、更灵活 | 更简洁、更受结构约束 |
| 对空间结构处理 | Flatten 后空间结构基本被打散 | 直接对通道做全局汇聚 |
| 常见用途 | 分类头、特征映射 | 分类收尾、轻量化结构 |
| 可解释性 | 相对弱一些 | 往往更自然一些 |
如果用一句话概括:
参数少的直接好处就是:
全连接层尤其在输入维度很大时,很容易引入大量参数。
而参数越多,模型越容易把训练集细节记住。
GAP 由于没有这种大规模矩阵映射,通常更不容易出现这种情况。
很多模型倾向于让卷积部分尽可能完成特征抽取和语义聚合,
最后只保留一个很轻的分类头。
GAP 正好符合这种设计思路。
如果最后通道数就等于类别数,那么每个通道在语义上会更接近某个类别响应。
这让模型尾部结构更清晰。
GAP 并不是任何时候都优于全连接层。
全连接层能够学习更复杂的特征组合关系。
如果任务特别依赖复杂非线性组合,单纯用 GAP 可能不够。
因为 GAP 几乎不做复杂映射,所以前面的卷积特征必须已经足够“接近可分类状态”。
如果前面的表示学得不够好,GAP 也很难补救。
如果你的任务不是简单分类,而是:
那么最后是否保留全连接层,要结合任务来判断。
虽然大家常说“全局池化”,但常见的主要有两种:
Global Average PoolingGlobal Max Pooling区别很直观:
如果特征图中只要有一个区域特别强就足以说明某类特征存在,那么全局最大池化会更敏感。
如果你更希望综合整个通道的总体激活情况,那么全局平均池化更平滑。
分类任务里,GAP 更常见。
假设某个通道的特征图是:
X ∈ R^(h x w)
那么全局平均池化的输出就是:
y = (1 / (h*w)) * ΣΣ X(i, j)
也就是把整张特征图上的值全部求平均。
如果有 C 个通道,那么输出就是一个长度为 C 的向量:
[y1, y2, ..., yC]
这个公式不复杂,但它背后表达的是一个很重要的设计思想:
先用 NumPy 感受一下。
假设输入是一个单样本的特征图,形状为:
(channels, height, width)
例如:
import numpy as np
x = np.array([
[[1, 2, 3],
[4, 5, 6],
[7, 8, 9]],
[[2, 2, 2],
[2, 2, 2],
[2, 2, 2]]
], dtype=np.float32)
gap = x.mean(axis=(1, 2))
print(gap)
输出会是:
[5. 2.]
解释如下:
52这就是最原始的 GAP。
PyTorch 里最常用的写法有两种。
AdaptiveAvgPool2d(1)import torch
import torch.nn as nn
x = torch.randn(4, 64, 7, 7) # batch=4, channel=64
gap = nn.AdaptiveAvgPool2d(1)
y = gap(x)
print(y.shape)
输出形状是:
torch.Size([4, 64, 1, 1])
如果要送进分类器,可以再展平:
y = y.view(y.size(0), -1)
print(y.shape)
import torch
x = torch.randn(4, 64, 7, 7)
y = x.mean(dim=(2, 3))
print(y.shape)
输出会是:
torch.Size([4, 64])
这种方式很直接,尤其适合快速验证。
下面先看一个比较传统的写法。
import torch
import torch.nn as nn
class CNNWithFC(nn.Module):
def __init__(self, num_classes=10):
super().__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 32, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2)
)
self.classifier = nn.Sequential(
nn.Flatten(),
nn.Linear(64 * 8 * 8, 128),
nn.ReLU(),
nn.Linear(128, num_classes)
)
def forward(self, x):
x = self.features(x)
x = self.classifier(x)
return x
这个结构的特点是:
Flatten + Linear 负责分类如果输入分辨率固定,这种方式没问题,但全连接层参数会比较多。
把上面的结构改成 GAP 版:
import torch
import torch.nn as nn
class CNNWithGAP(nn.Module):
def __init__(self, num_classes=10):
super().__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 32, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(64, num_classes, kernel_size=1)
)
self.gap = nn.AdaptiveAvgPool2d(1)
def forward(self, x):
x = self.features(x)
x = self.gap(x)
x = x.view(x.size(0), -1)
return x
这里最后一层 1x1 卷积把通道数直接映射成类别数。
之后用 GAP 把每个通道压成一个值,最终得到分类输出。
这种结构的思路非常清晰:
如果你在实际项目里做选择,可以先按下面的原则判断。
很多现代 CNN 分类网络,会倾向于:
而不是:
你可以把两者想成两种不同的“收尾方法”:
所以:
这个类比不严格,但很有助于建立直觉。
有些结构是:
有些结构是:
所以 GAP 并不总是意味着彻底消灭所有线性层,它只是大幅简化了尾部结构。
1x1 卷积经常和 GAP 搭配因为它可以很方便地调整通道数,把最后通道映射到类别数或更紧凑的语义空间。
全连接层通常强依赖固定输入尺寸。
而 GAP 对空间维度更灵活,只要前面卷积能跑通,它就能把不同大小的特征图压成固定长度向量。
这一点在工程里很实用。
如果把本文内容收缩成最核心的几个结论,可以记住下面这些:
如果再用一句话概括:
全连接层更像“高容量分类器”,全局平均池化更像“参数高效的结构化收尾方式”。
下面给一个非常小的可运行片段,用来比较两种网络输出形状。
import torch
x = torch.randn(2, 3, 32, 32)
model_fc = CNNWithFC(num_classes=10)
model_gap = CNNWithGAP(num_classes=10)
out_fc = model_fc(x)
out_gap = model_gap(x)
print("FC output shape:", out_fc.shape)
print("GAP output shape:", out_gap.shape)
如果定义无误,两者输出都会是:
[batch_size, num_classes]
也就是:
C x H x W -> C*H*W
input_dim x output_dim + output_dim
y = (1 / (h*w)) * ΣΣ X(i, j)
只要把这三条关系理解透,FC 和 GAP 的差异基本就很清楚了。