2018-12-25
Logistic Regression,中文通常叫逻辑回归。名字里带“回归”,但它最常见的用途其实是分类,尤其是二分类。
比如:
线性回归的形式很简单:
y = w1x1 + w2x2 + ... + wnxn + b
也可以写成向量形式:
y = w·x + b
如果目标是预测房价、销量、温度这类连续值,线性回归很自然。
但如果目标是二分类,比如:
0 = 不点击
1 = 点击
直接用线性回归就会有问题。
因为线性模型输出范围是整个实数轴:
(-∞, +∞)
而概率必须落在:
[0, 1]
所以我们需要一个函数,把任意实数压到 0 到 1 之间。
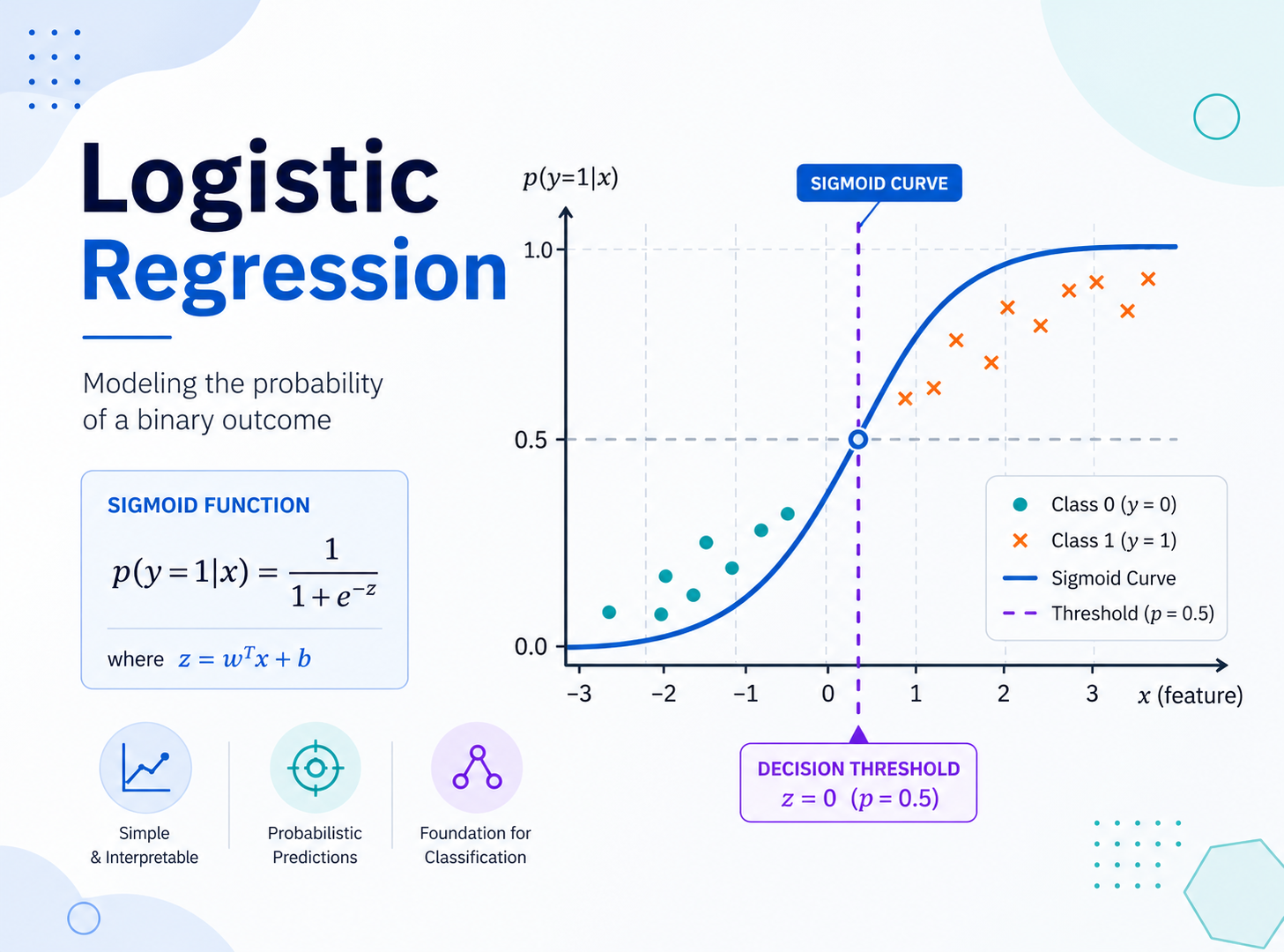
这个函数就是 sigmoid。
Sigmoid 函数定义为:
σ(z) = 1 / (1 + e^(-z))
其中:
z = w·x + b
它的输出范围是:
0 < σ(z) < 1
因此可以把它解释成概率。

当 z = 0 时:
σ(0) = 1 / (1 + e^0) = 1 / 2 = 0.5
当 z 很大时,σ(z) 接近 1。
当 z 很小时,σ(z) 接近 0。
于是逻辑回归的预测形式就是:
p(y = 1 | x) = σ(w·x + b)
如果概率大于某个阈值,比如 0.5,就预测为 1;否则预测为 0。
理解逻辑回归时,一个很关键的概念是 odds,中文可以叫“几率”。
如果某件事发生的概率是 p,不发生的概率是 1 - p,那么 odds 定义为:
odds = p / (1 - p)
举个例子,如果点击概率是:
p = 0.8
那么不点击概率是:
1 - p = 0.2
odds 就是:
0.8 / 0.2 = 4
意思是:发生与不发生的比例是 4:1。
如果:
p = 0.5
那么:
odds = 0.5 / 0.5 = 1
发生和不发生一样可能。
odds 的取值范围是:
(0, +∞)
对 odds 取自然对数,就得到 logit:
logit(p) = log(p / (1 - p))
logit 的取值范围是整个实数:
(-∞, +∞)
这就很妙了。
线性模型 w·x + b 的输出也是整个实数,所以逻辑回归可以理解为:
log(p / (1 - p)) = w·x + b
也就是说,逻辑回归不是直接对概率 p 做线性建模,而是对概率对应的 logit 做线性建模。
这也是为什么 Logistic Regression 可以看成对 logit 的线性拟合。
从下面这个式子开始:
log(p / (1 - p)) = z
两边取指数:
p / (1 - p) = e^z
整理:
p = e^z(1 - p)
p = e^z - e^z p
p(1 + e^z) = e^z
p = e^z / (1 + e^z)
上下同时除以 e^z:
p = 1 / (1 + e^(-z))
这就是 sigmoid 函数。
所以 sigmoid 不是凭空出现的,它可以从 logit 线性建模自然推导出来。
逻辑回归预测的是概率:
p = σ(w·x + b)
如果使用 0.5 作为分类阈值:
p >= 0.5 -> 预测为 1
p < 0.5 -> 预测为 0
由于:
σ(0) = 0.5
所以分类边界对应:
w·x + b = 0
这就是逻辑回归的决策边界。

在二维特征下,边界是一条直线。
在更高维特征下,边界是一个超平面。
这也说明了逻辑回归的一个特点:它本质上是线性分类器。
如果数据本身不是线性可分,可以通过特征工程、多项式特征,或者换用更复杂的模型来处理。
线性回归常用平方误差:
MSE = 1/n × Σ(y_i - y_hat_i)^2
但逻辑回归通常不使用平方误差,而是使用对数损失,也叫交叉熵损失。
对于单个样本:
Loss = -[y log(p) + (1 - y) log(1 - p)]
其中:
y 是真实标签,取 0 或 1p 是模型预测为 1 的概率如果真实标签 y = 1:
Loss = -log(p)
此时 p 越接近 1,损失越小。
如果真实标签 y = 0:
Loss = -log(1 - p)
此时 p 越接近 0,损失越小。
把两种情况合在一个公式里,就是交叉熵。
对于整个数据集:
J(w, b) = -1/n × Σ[y_i log(p_i) + (1 - y_i) log(1 - p_i)]
训练逻辑回归,就是寻找一组 w 和 b,让这个损失尽可能小。
逻辑回归虽然简单,但也会过拟合。
如果特征很多,或者特征之间存在复杂组合,模型可能在训练集上表现很好,但泛化能力不好。
常见做法是在损失函数中加入正则化。
L2 正则化:
J = Loss + λΣw_j²
它会惩罚过大的权重,让模型更平滑。
L1 正则化:
J = Loss + λΣ|w_j|
它可能把部分权重压到 0,从而产生特征选择效果。
在 sklearn 中,逻辑回归默认会带正则化,所以参数解释时要注意这一点。
下面用 NumPy 写一个最小版本,帮助理解训练过程。
import numpy as np
def sigmoid(z):
return 1 / (1 + np.exp(-z))
def binary_cross_entropy(y, p):
eps = 1e-12
p = np.clip(p, eps, 1 - eps)
return -np.mean(y * np.log(p) + (1 - y) * np.log(1 - p))
class SimpleLogisticRegression:
def __init__(self, lr=0.1, n_iter=1000):
self.lr = lr
self.n_iter = n_iter
self.w = None
self.b = 0.0
def fit(self, X, y):
n_samples, n_features = X.shape
self.w = np.zeros(n_features)
self.b = 0.0
for _ in range(self.n_iter):
z = X @ self.w + self.b
p = sigmoid(z)
dw = X.T @ (p - y) / n_samples
db = np.mean(p - y)
self.w -= self.lr * dw
self.b -= self.lr * db
return self
def predict_proba(self, X):
return sigmoid(X @ self.w + self.b)
def predict(self, X, threshold=0.5):
return (self.predict_proba(X) >= threshold).astype(int)
造一组简单数据测试:
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
X, y = make_classification(
n_samples=500,
n_features=2,
n_redundant=0,
n_informative=2,
random_state=42
)
X_train, X_test, y_train, y_test = train_test_split(
X,
y,
test_size=0.2,
random_state=42
)
model = SimpleLogisticRegression(lr=0.1, n_iter=2000)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
print("accuracy:", accuracy_score(y_test, y_pred))
print("weights:", model.w)
print("bias:", model.b)
这个版本没有做各种工程优化,但核心逻辑已经包含:
z = Xw + b实际项目中,更常用 sklearn。
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
data = load_breast_cancer()
X = data.data
y = data.target
X_train, X_test, y_train, y_test = train_test_split(
X,
y,
test_size=0.2,
random_state=42,
stratify=y
)
model = Pipeline([
("scaler", StandardScaler()),
("clf", LogisticRegression(max_iter=1000))
])
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
print("accuracy:", accuracy_score(y_test, y_pred))
print(confusion_matrix(y_test, y_pred))
print(classification_report(y_test, y_pred, target_names=data.target_names))
这里用了 StandardScaler。
逻辑回归对特征尺度比较敏感,尤其在带正则化时,标准化通常是一个好习惯。
逻辑回归不只是给类别,也可以给概率。
proba = model.predict_proba(X_test[:5])
print(proba)
输出形状一般是:
n_samples × n_classes
二分类时,每行通常类似:
[预测为 0 的概率, 预测为 1 的概率]
如果只想看正类概率:
positive_proba = model.predict_proba(X_test)[:, 1]
这在风控、推荐、排序、阈值调整里很常用。
默认情况下:
p >= 0.5 -> 预测为正类
但很多业务场景中,阈值可以调整。
比如风控系统更怕漏掉风险交易,可能会降低阈值,让更多样本被判为风险。
positive_proba = model.predict_proba(X_test)[:, 1]
threshold = 0.3
y_pred_custom = (positive_proba >= threshold).astype(int)
阈值降低后,通常召回率会上升,但误报也可能增加。
所以阈值不是数学上固定的,而是要结合业务成本来选。
逻辑回归适合这些场景:
典型例子包括:
它的优点是简单、稳定、可解释。
权重 w 可以反映特征对 logit 的影响方向:
但要注意,前提是特征尺度和特征含义要合理。
逻辑回归的优点:
它的局限也很明显:
如果数据明显非线性,可以考虑:
Logistic Regression 虽然名字叫回归,但常用于分类。
它的核心思想是:
先用线性模型得到 z = w·x + b
再通过 sigmoid 把 z 映射成概率
从 logit 角度看,它等价于:
log(p / (1 - p)) = w·x + b
也就是对事件发生概率的 log odds 做线性建模。
训练时通常使用交叉熵损失,通过优化参数让真实标签对应的预测概率更高。
逻辑回归不复杂,但很经典。它既能帮助我们理解概率分类模型,也能作为很多业务问题的可靠基线。