2018-10-08
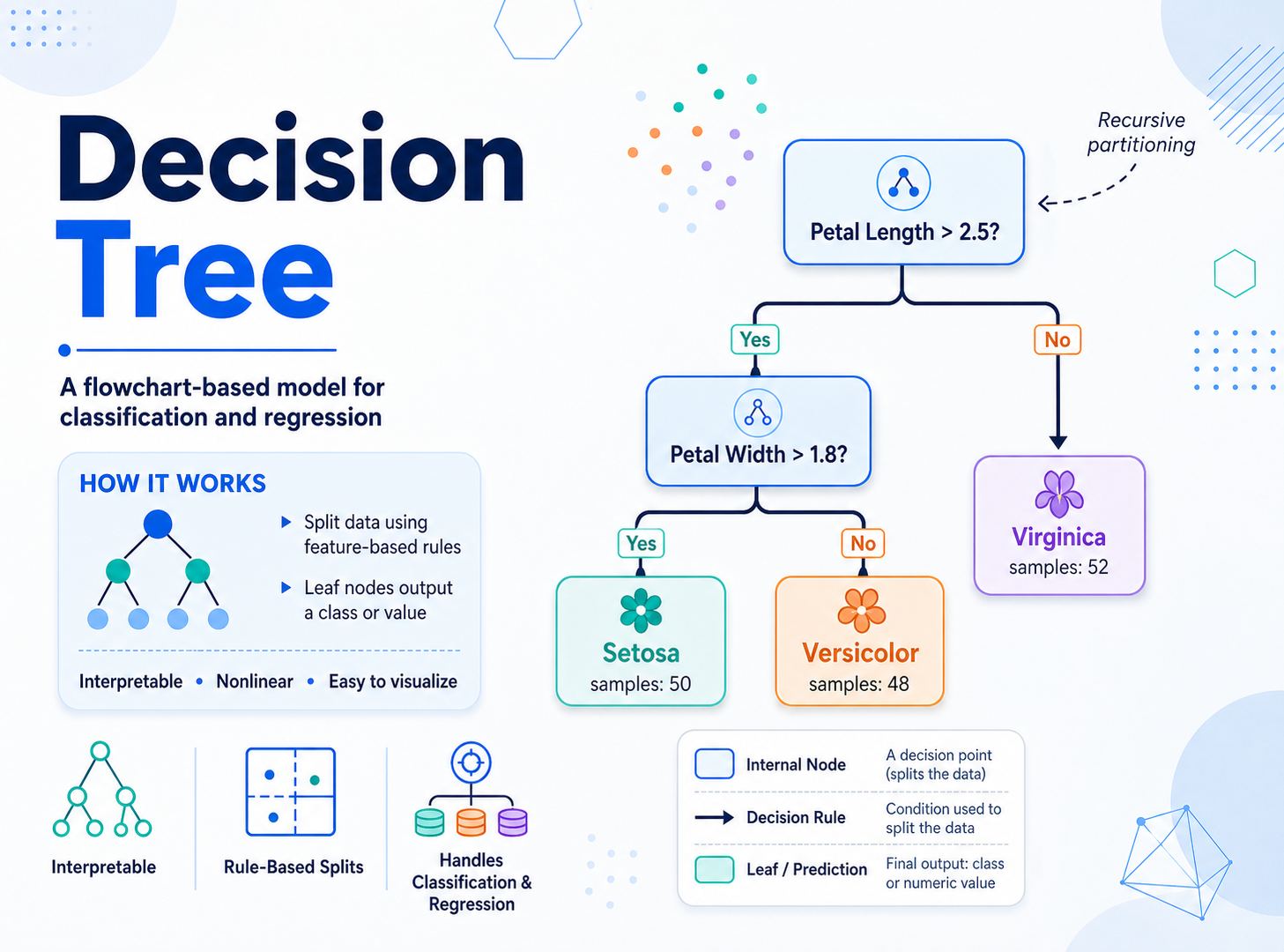
决策树是一种非常直观的机器学习模型。它的思路很像人在做判断:先问一个问题,根据答案走到不同分支,再继续问下一个问题,最后得到一个预测结果。
判断一个用户是否会购买商品,决策树可能会这样拆:
是否浏览过商品详情?
├── 是:是否加入购物车?
│ ├── 是:购买概率高
│ └── 否:购买概率中等
└── 否:购买概率低
这种结构容易理解,也容易解释,所以决策树经常被用作机器学习入门模型,也常被用在需要模型可解释性的业务中。
在 Python 里,sklearn 提供了非常方便的决策树实现:
DecisionTreeClassifier:分类决策树DecisionTreeRegressor:回归决策树决策树的核心任务是:找到一系列划分规则,把数据一步步切开,让每个叶子节点里的样本尽量“纯”。
对于分类问题,所谓“纯”,就是一个节点里的样本尽量属于同一个类别。
例如一个节点里有 100 个样本:
90 个正样本
10 个负样本
这个节点比较纯。
如果是:
50 个正样本
50 个负样本
这个节点就比较混乱。
决策树训练时会不断寻找最合适的特征和切分点,让划分后的子节点更加纯。
假设我们要预测用户是否会买课,数据里有两个特征:
决策树可能会学出这样的规则:
学习时长 <= 3
├── 是:不购买
└── 否:是否收藏课程?
├── 是:购买
└── 否:不购买
这个模型的预测过程非常清楚:每个样本从根节点开始,根据条件一步步往下走,最后走到某个叶子节点,叶子节点的类别就是预测结果。
在 sklearn 中,分类决策树默认使用 Gini 不纯度来选择划分。
一个节点的 Gini 不纯度定义为:
Gini = 1 - Σ p_i²
其中:
p_i 表示当前节点中第 i 类样本所占比例举个例子,一个节点里有两类样本:
正样本比例 p1 = 0.8
负样本比例 p2 = 0.2
那么:
Gini = 1 - (0.8² + 0.2²)
= 1 - (0.64 + 0.04)
= 0.32
如果一个节点里全是同一类:
p1 = 1
p2 = 0
那么:
Gini = 1 - (1² + 0²) = 0
Gini 为 0 表示节点已经完全纯净。
除了 Gini,决策树也可以使用信息熵。
信息熵衡量的是不确定性:
Entropy = -Σ p_i log₂(p_i)
如果一个节点越混乱,熵越大;如果一个节点越纯,熵越小。
对于二分类问题,如果正负样本各占一半,不确定性最大:
p1 = 0.5
p2 = 0.5
对应的信息熵是:
Entropy = -0.5 log₂(0.5) - 0.5 log₂(0.5)
= 1
如果一个节点全是同一类,熵为 0。
信息增益表示划分前后不确定性减少了多少:
Gain = Entropy(parent) - Σ weight_child × Entropy(child)
决策树会倾向选择信息增益更大的划分。
在 sklearn 中可以通过 criterion 参数指定:
DecisionTreeClassifier(criterion="gini")
DecisionTreeClassifier(criterion="entropy")
分类树预测类别,回归树预测连续值。
比如预测房价、销量、温度、收入等。
回归树的叶子节点通常会输出该叶子节点内训练样本目标值的平均值。
例如某个叶子节点里有 4 个样本,真实值分别是:
100, 120, 130, 150
那么该叶子节点的预测值可以是:
(100 + 120 + 130 + 150) / 4 = 125
回归树在寻找划分时,常用目标是让子节点内的误差更小。
常见的平方误差可以写成:
MSE = 1/n × Σ(y_i - y_mean)²
其中:
y_i 是样本真实值y_mean 是当前节点样本目标值的平均值n 是当前节点样本数量回归树会寻找让划分后总体 MSE 更小的特征和切分点。
先看一个最小可运行示例。
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score, classification_report
iris = load_iris()
X = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(
X,
y,
test_size=0.2,
random_state=42,
stratify=y
)
model = DecisionTreeClassifier(
criterion="gini",
max_depth=3,
random_state=42
)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
print("accuracy:", accuracy_score(y_test, y_pred))
print(classification_report(y_test, y_pred, target_names=iris.target_names))
这里几个参数很常见:
criterion:划分指标,可以是 "gini" 或 "entropy"max_depth:树的最大深度random_state:随机种子,便于结果复现stratify:保持训练集和测试集类别比例接近回归任务可以使用 DecisionTreeRegressor。
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeRegressor
from sklearn.metrics import mean_squared_error, r2_score
X, y = make_regression(
n_samples=500,
n_features=5,
noise=10,
random_state=42
)
X_train, X_test, y_train, y_test = train_test_split(
X,
y,
test_size=0.2,
random_state=42
)
model = DecisionTreeRegressor(
max_depth=4,
random_state=42
)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
print("mse:", mean_squared_error(y_test, y_pred))
print("r2:", r2_score(y_test, y_pred))
回归任务常看的指标:
mean_squared_error:均方误差,越小越好r2_score:拟合优度,越接近 1 通常越好决策树很强,也很容易“想太多”。
如果不加限制,它可能会把训练数据切得非常细,每个叶子节点里只剩很少样本,甚至把训练集里的噪声也记住。
这会导致训练集表现很好,测试集表现变差。
常见表现是:
训练集准确率很高
测试集准确率明显低
控制过拟合常用参数有:
DecisionTreeClassifier(
max_depth=4,
min_samples_split=10,
min_samples_leaf=5,
max_leaf_nodes=20
)
这些参数的含义:
max_depth:限制树的最大深度min_samples_split:节点至少有多少样本才允许继续划分min_samples_leaf:叶子节点至少保留多少样本max_leaf_nodes:最多允许多少个叶子节点一般来说,限制越强,模型越简单;限制越弱,模型越复杂。
决策树最大的优点之一是可解释性强。可以把树画出来看规则。
import matplotlib.pyplot as plt
from sklearn.tree import plot_tree
plt.figure(figsize=(12, 8))
plot_tree(
model,
feature_names=iris.feature_names,
class_names=iris.target_names,
filled=True,
rounded=True
)
plt.show()
图里通常会看到:
如果树太深,可视化会变得很难读。所以可解释性并不等于可以无限长,适当限制深度反而更容易解释。
决策树可以输出特征重要性。
import pandas as pd
importance = pd.DataFrame({
"feature": iris.feature_names,
"importance": model.feature_importances_
}).sort_values("importance", ascending=False)
print(importance)
feature_importances_ 表示每个特征对降低不纯度的贡献。
它可以帮助我们粗略判断哪些特征更有用。
不过要注意,特征重要性不是因果关系。某个特征重要,不代表它一定是业务原因,也可能只是和真正原因高度相关。
决策树适合规则清晰、需要解释、特征关系非线性的场景。
常见应用包括:
它特别适合做基线模型。
比如你要做一个分类任务,可以先训练一个浅层决策树,看看大概哪些特征有用,模型能达到什么水平,再考虑更复杂的模型。
决策树有几个非常明显的优点。
它容易理解。相比很多黑盒模型,决策树可以把预测逻辑展示成规则路径。
它对特征缩放不敏感。很多模型需要标准化或归一化,但决策树通常不需要。
它能处理非线性关系。比如某个特征在不同区间有不同影响,决策树可以通过分裂自然表达出来。
它可以同时处理分类和回归任务。
决策树也有短板。
最明显的是容易过拟合。树长得太深,训练集效果会很好,但泛化能力可能变差。
它对数据扰动比较敏感。训练数据稍有变化,树结构可能发生明显变化。
单棵树的预测能力通常有限。在复杂任务中,随机森林、GBDT、XGBoost、LightGBM 这类集成模型通常表现更强。
另外,决策树的分裂方式是贪心的。它每一步都选择当前看起来最好的划分,但不保证全局最优。
如果目标变量是类别,用分类树:
from sklearn.tree import DecisionTreeClassifier
例如:
如果目标变量是连续数值,用回归树:
from sklearn.tree import DecisionTreeRegressor
例如:
实际建模时,通常会把训练、预测、评估放在一起。
import pandas as pd
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
data = load_breast_cancer()
X = pd.DataFrame(data.data, columns=data.feature_names)
y = data.target
X_train, X_test, y_train, y_test = train_test_split(
X,
y,
test_size=0.2,
random_state=42,
stratify=y
)
clf = DecisionTreeClassifier(
criterion="gini",
max_depth=4,
min_samples_leaf=5,
random_state=42
)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print("accuracy:", accuracy_score(y_test, y_pred))
print("confusion matrix:")
print(confusion_matrix(y_test, y_pred))
print(classification_report(y_test, y_pred, target_names=data.target_names))
feature_importance = pd.DataFrame({
"feature": X.columns,
"importance": clf.feature_importances_
}).sort_values("importance", ascending=False)
print(feature_importance.head(10))
如果模型明显过拟合,可以尝试:
DecisionTreeClassifier(
max_depth=3,
min_samples_split=20,
min_samples_leaf=10
)
如果模型太简单,训练集和测试集表现都不好,可以适当放宽:
DecisionTreeClassifier(
max_depth=8,
min_samples_split=5,
min_samples_leaf=2
)
也可以用网格搜索:
from sklearn.model_selection import GridSearchCV
from sklearn.tree import DecisionTreeClassifier
param_grid = {
"max_depth": [3, 4, 5, 6, None],
"min_samples_split": [2, 5, 10, 20],
"min_samples_leaf": [1, 2, 5, 10],
"criterion": ["gini", "entropy"],
}
grid = GridSearchCV(
DecisionTreeClassifier(random_state=42),
param_grid=param_grid,
cv=5,
scoring="accuracy"
)
grid.fit(X_train, y_train)
print(grid.best_params_)
print(grid.best_score_)
调参时不要只看训练集效果。决策树很容易在训练集上表现漂亮,但真正重要的是验证集或测试集表现。
决策树是一种结构清晰、解释性强、上手简单的机器学习模型。
它的核心思想是不断寻找最优划分,让节点里的样本越来越纯。分类树常用 Gini 或信息熵衡量纯度,回归树常用平方误差衡量预测误差。
用 sklearn 训练决策树非常方便:
DecisionTreeClassifier()
DecisionTreeRegressor()
但使用时要特别注意过拟合。max_depth、min_samples_split、min_samples_leaf 这些参数非常关键。
如果你刚开始做一个机器学习任务,决策树是一个很适合的起点。它不一定是最终效果最强的模型,但它能快速给你一套可解释的规则,帮助你理解数据和特征之间的关系。