2018-10-17
卷积神经网络听起来很硬核,但很多常见组件其实都在解决很朴素的问题:让网络更好训练、让梯度更稳定、让模型别太容易记住训练集。
神经网络如果只有线性变换,本质上无论堆多少层,最后仍然可以等价成一个线性模型。
所以网络中间需要激活函数。激活函数的作用是引入非线性,让模型能表达更复杂的关系。
在卷积神经网络中,ReLU 是非常常见的激活函数:
ReLU(x) = max(0, x)
它的含义很简单:

从图上可以看到,ReLU 在正半轴是线性的,在负半轴直接压成 0。
它的优点很明显:
不过 ReLU 也有一个问题:如果某些神经元长期落在负半轴,它们的输出就是 0,梯度也可能一直为 0,这类神经元就很难再被更新。
这就是常说的 “dying ReLU” 问题。
Leaky ReLU 是对 ReLU 的一个小改造。
它不是把负数直接变成 0,而是保留一个很小的斜率:
LeakyReLU(x) =
x, x > 0
αx, x <= 0
其中 α 是一个很小的正数,比如 0.01。
这样做的好处是:即使输入落在负半轴,神经元也不是完全没有梯度。
直观理解:
ReLU:负数区域直接关门
Leaky ReLU:负数区域留了一条缝
这条缝不一定让模型必然更强,但它能降低部分神经元彻底失活的风险。
用 PyTorch 写起来很直接:
import torch
import torch.nn as nn
x = torch.tensor([-2.0, -1.0, 0.0, 1.0, 2.0])
relu = nn.ReLU()
leaky_relu = nn.LeakyReLU(negative_slope=0.01)
print(relu(x))
print(leaky_relu(x))
输出大致是:
tensor([0., 0., 0., 1., 2.])
tensor([-0.0200, -0.0100, 0.0000, 1.0000, 2.0000])
如果写在卷积网络里,一般像这样:
import torch.nn as nn
block = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=32, kernel_size=3, padding=1),
nn.BatchNorm2d(32),
nn.LeakyReLU(negative_slope=0.01),
)
这种 Conv -> BN -> Activation 是很常见的结构。
神经网络参数很多时,很容易过拟合。
过拟合可以理解为:模型把训练数据记得太熟,结果在新数据上表现反而不好。
Dropout 的思路很有意思:训练时随机丢弃一部分神经元,让网络不能总是依赖固定的几条路径。

假设某一层有很多神经元,训练时每一轮随机让一部分神经元暂时失效。这样网络被迫学习更分散、更稳健的特征表达。
它有点像告诉模型:
别总盯着几个特征用,其他特征也练练。
Dropout 的常见公式可以写成:
m ~ Bernoulli(p)
y = x * m / p
其中:
m 是随机掩码p 是保留概率x 是输入y 是 Dropout 后的输出除以 p 是为了让训练阶段输出的期望和推理阶段保持接近。
Dropout 只在训练阶段随机丢弃神经元。
推理阶段不会随机丢弃,而是使用完整网络。
在 PyTorch 中,这由模型状态控制:
model.train() # 开启训练模式,Dropout 生效
model.eval() # 开启推理模式,Dropout 关闭
这是一个很常见的坑。如果评估模型时忘了调用 model.eval(),Dropout 仍然可能在工作,预测结果就会不稳定。
全连接层里常见写法:
import torch.nn as nn
model = nn.Sequential(
nn.Linear(128, 64),
nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(64, 10)
)
卷积网络里可以用 Dropout2d:
model = nn.Sequential(
nn.Conv2d(3, 32, kernel_size=3, padding=1),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.Dropout2d(p=0.2),
nn.Conv2d(32, 64, kernel_size=3, padding=1),
)
一般来说:
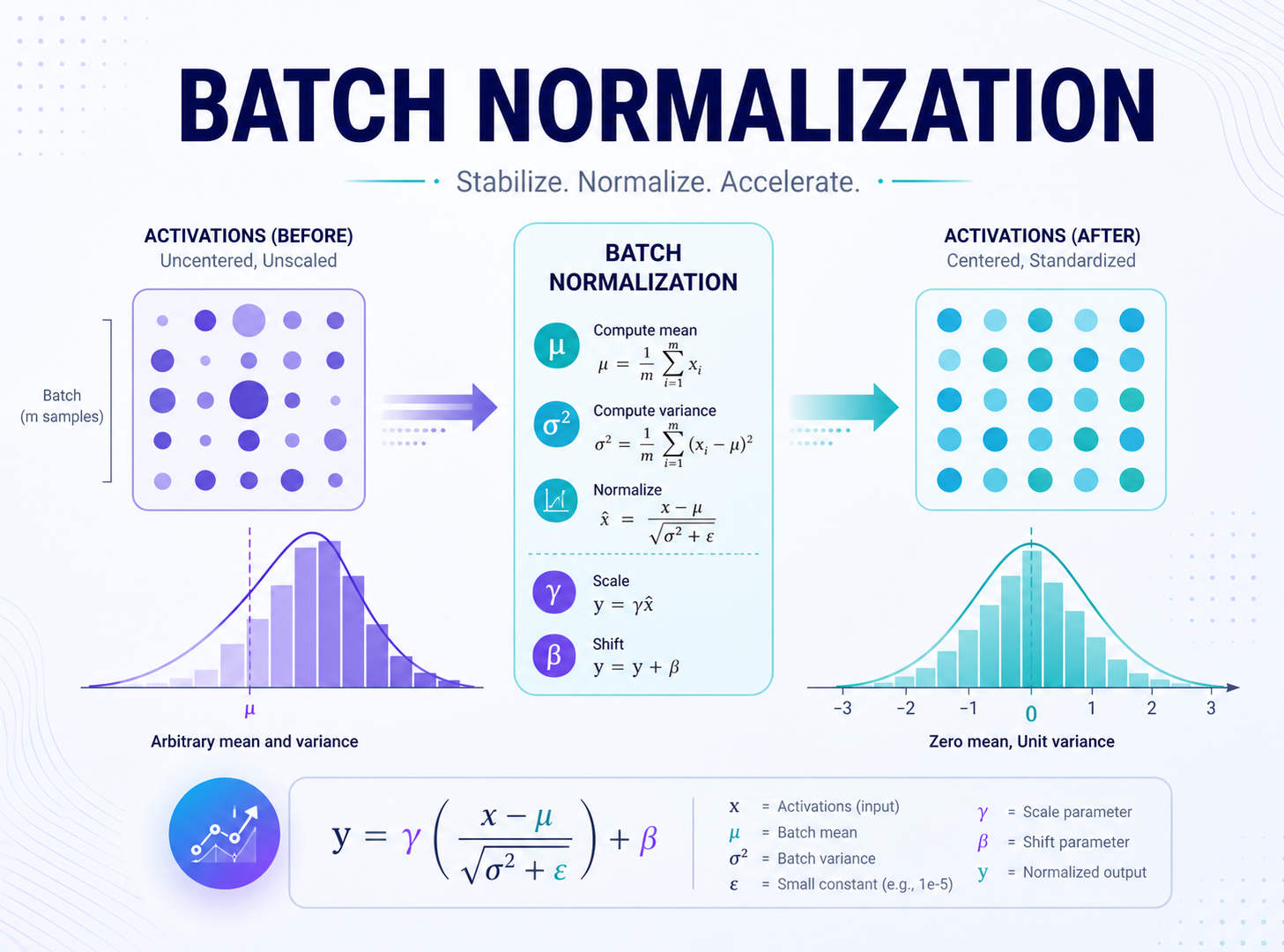
DropoutDropout2dBatch Normalization 通常简称 BN。
它的核心思路是:对一个 batch 内的中间层输出做归一化,让数据分布更稳定。

对于一批输入 x,BN 大致做下面几步:
μ = mean(x)
σ² = var(x)
x_hat = (x - μ) / sqrt(σ² + ε)
y = γ * x_hat + β
其中:
μ 是 batch 均值σ² 是 batch 方差ε 是一个很小的数,用来避免除零γ 和 β 是可学习参数归一化之后,为什么还要乘 γ 加 β?
因为完全标准化可能限制网络表达能力。γ 和 β 让网络可以自己学习是否需要把数据缩放或平移回来。
可以理解为:
先把分布拉稳,再把调节权交还给模型。
BN 常见作用包括:
不过 BN 不是万能的。
如果 batch 很小,均值和方差估计可能不稳定。这时可以考虑 GroupNorm、LayerNorm 等替代方案。
全连接层输出通常使用 BatchNorm1d:
model = nn.Sequential(
nn.Linear(128, 64),
nn.BatchNorm1d(64),
nn.ReLU(),
nn.Linear(64, 10)
)
卷积网络里通常使用 BatchNorm2d:
model = nn.Sequential(
nn.Conv2d(3, 32, kernel_size=3, padding=1),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.Conv2d(32, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(),
)
这里的 32 和 64 对应的是通道数,也就是卷积层的 out_channels。
下面是一个包含 Conv、BN、LeakyReLU 和 Dropout 的小型卷积网络。
import torch
import torch.nn as nn
class SmallCNN(nn.Module):
def __init__(self, num_classes=10):
super().__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 32, kernel_size=3, padding=1),
nn.BatchNorm2d(32),
nn.LeakyReLU(negative_slope=0.01),
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(32, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.LeakyReLU(negative_slope=0.01),
nn.MaxPool2d(kernel_size=2),
nn.Dropout2d(p=0.2),
)
self.classifier = nn.Sequential(
nn.Flatten(),
nn.Linear(64 * 8 * 8, 128),
nn.BatchNorm1d(128),
nn.LeakyReLU(negative_slope=0.01),
nn.Dropout(p=0.5),
nn.Linear(128, num_classes),
)
def forward(self, x):
x = self.features(x)
x = self.classifier(x)
return x
model = SmallCNN(num_classes=10)
x = torch.randn(4, 3, 32, 32)
y = model(x)
print(y.shape)
输出:
torch.Size([4, 10])
这个网络的结构可以概括为:
Conv -> BN -> LeakyReLU -> Pool
Conv -> BN -> LeakyReLU -> Pool
Dropout
Linear -> BN -> LeakyReLU -> Dropout -> Linear
常见卷积块顺序是:
Conv -> BN -> ReLU
或:
Conv -> BN -> LeakyReLU
Dropout 通常放在激活之后,或者放在全连接层之间:
Linear -> Activation -> Dropout -> Linear
也有人会根据实验调整顺序。对于初学和大多数常规任务,先使用清晰稳定的结构就够了,不必一开始就追求花哨组合。
如果使用 Keras,也可以很简洁:
import tensorflow as tf
from tensorflow.keras import layers, models
model = models.Sequential([
layers.Conv2D(32, 3, padding="same", input_shape=(32, 32, 3)),
layers.BatchNormalization(),
layers.LeakyReLU(alpha=0.01),
layers.MaxPooling2D(),
layers.Conv2D(64, 3, padding="same"),
layers.BatchNormalization(),
layers.LeakyReLU(alpha=0.01),
layers.MaxPooling2D(),
layers.Dropout(0.2),
layers.Flatten(),
layers.Dense(128),
layers.BatchNormalization(),
layers.LeakyReLU(alpha=0.01),
layers.Dropout(0.5),
layers.Dense(10, activation="softmax"),
])
model.summary()
如果训练分类任务,可以这样编译:
model.compile(
optimizer="adam",
loss="sparse_categorical_crossentropy",
metrics=["accuracy"]
)
可以把它们放在一张表里看:
| 模块 | 主要作用 | 常见位置 |
|---|---|---|
| ReLU | 引入非线性,计算简单 | 卷积层或全连接层之后 |
| Leaky ReLU | 缓解负半轴神经元失活 | 卷积层或全连接层之后 |
| Dropout | 降低过拟合,减少共适应 | 全连接层之间,或卷积块后 |
| BatchNorm | 稳定中间层分布,加速训练 | 卷积层或全连接层之后、激活前 |
如果用一句话总结:
Activation 负责表达能力,Dropout 负责别太依赖局部特征,BN 负责让训练过程更稳。
Dropout 不是越大越好。
如果 p 设置太大,很多信息都会被丢掉,模型可能学不动。
BN 也不是所有场景都稳定。
当 batch 很小,BN 统计的均值和方差可能很抖,这时模型效果可能不如预期。
Leaky ReLU 不一定总比 ReLU 好。
它只是给负半轴保留梯度,具体效果还是要看任务和数据。
还有一个容易忽略的点:训练和推理模式一定要切换正确。
model.train()
# 训练
model.eval()
# 验证或推理
BN 和 Dropout 都会受到这个状态影响。
卷积神经网络里,BN、Dropout 和 Leaky ReLU 都是非常常见的组件。
ReLU 简单高效,但负半轴可能出现神经元失活;Leaky ReLU 给负半轴保留了一个小斜率,让梯度还有机会通过。
Dropout 在训练阶段随机丢弃部分神经元,减少模型对某些局部路径的依赖,从而降低过拟合风险。
Batch Normalization 对中间层输出做归一化,再通过可学习的缩放和平移恢复表达能力,让训练过程更稳定。
实践中,一个很常见的卷积块就是:
Conv -> BN -> LeakyReLU
再根据任务复杂度和过拟合情况,适当加入 Dropout。
这些模块单独看都不复杂,真正关键的是理解它们分别在帮网络解决什么问题。理解之后,再看各种 CNN 结构,就会清楚很多。