2018-08-20
交叉熵是机器学习里最常见的损失函数之一,只要你接触过分类模型,几乎一定会遇到它。
很多人第一次看到交叉熵,会觉得它有点抽象:
1 的位置要重点计算?其实交叉熵并不神秘。
如果把它放回“概率预测是否准确”这个问题里,它的逻辑非常自然。
可以先记住一句话:
交叉熵用来衡量“模型给真实答案分配了多大概率”。
如果模型对真实类别给出的概率越高,说明预测越靠谱,交叉熵就越小。
如果模型对真实类别给出的概率越低,说明预测越差,交叉熵就越大。
所以从作用上看,交叉熵本质上是在做一件事:
这就是它特别适合分类问题的原因。
理解交叉熵,一个很常见的入口是“信息量”。
在信息论里,一个事件发生后带来的信息量可以写成:
I(x) = -log p(x)
这条式子表达的意思并不复杂:
把这个思路放到分类里:
这正是交叉熵的直觉来源。
二分类里,真实标签通常记为:
y = 1 表示正类y = 0 表示负类模型输出一个概率 p,表示“样本属于正类的概率”。
这时,二分类交叉熵通常写成:
L = -[y log(p) + (1 - y) log(1 - p)]
这是最常见的一条公式。
分两种情况看就很清楚。
y = 1公式变成:
L = -log(p)
这说明:
p 很接近 1,那么损失很小p 很接近 0,那么损失很大这很符合直觉,因为真实标签就是正类,模型本来就应该把正类概率打高。
y = 0公式变成:
L = -log(1 - p)
这说明:
p 很接近 0,那么损失很小p 很接近 1,那么损失很大也符合直觉,因为真实标签是负类,模型就不该给正类很高概率。
假设真实标签是 y = 1。
如果模型输出:
p = 0.9那么损失大约是:
-log(0.9) ≈ 0.105
如果模型输出:
p = 0.5那么损失大约是:
-log(0.5) ≈ 0.693
如果模型输出:
p = 0.1那么损失大约是:
-log(0.1) ≈ 2.303
可以看到:
如果是多分类问题,模型通常会输出一个概率分布:
[p1, p2, p3, ..., pn]
其中:
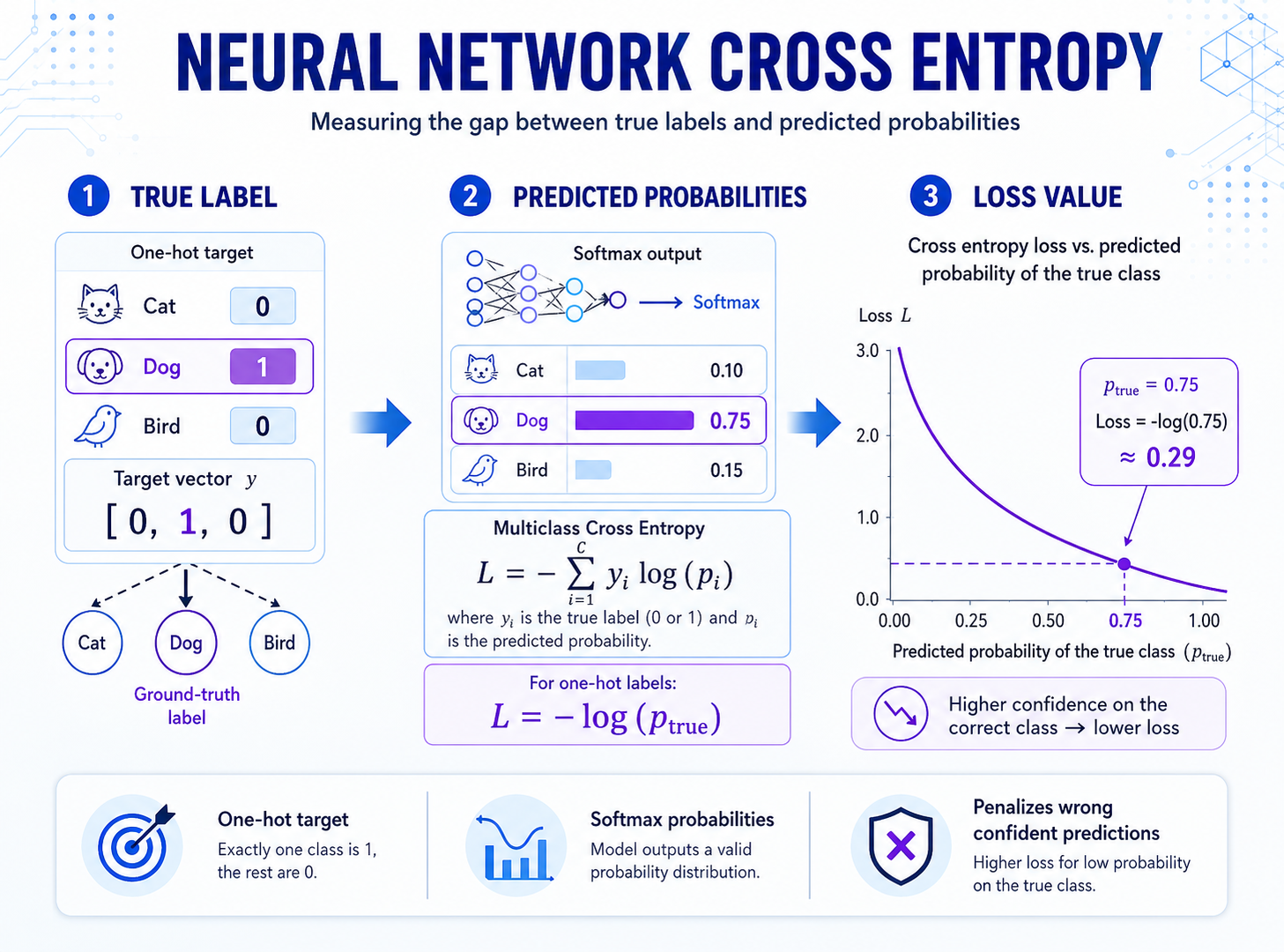
pi 都表示样本属于第 i 类的概率1如果真实标签采用 one-hot 形式表示,那么多分类交叉熵可以写成:
L = -Σ yi log(pi)
这里:
yi 是真实标签pi 是模型预测该类别的概率因为 one-hot 标签里只有真实类别对应的位置是 1,其他位置都是 0。
例如三分类任务里,真实标签如果是第 2 类:
y = [0, 1, 0]
模型预测概率如果是:
p = [0.2, 0.7, 0.1]
那么交叉熵就是:
L = -(0*log(0.2) + 1*log(0.7) + 0*log(0.1))
= -log(0.7)
所以多分类交叉熵本质上还是那句话:
真实类别概率越高,损失越小。
很多文章会把交叉熵、熵、KL 散度放在一起讲。
如果你只是做模型训练,其实不用把它们想得太复杂。
可以先用下面这组关系来理解:
它们之间有一个常见关系式:
H(P, Q) = H(P) + D_KL(P || Q)
这里:
H(P, Q) 是交叉熵H(P) 是真实分布的熵D_KL(P || Q) 是 KL 散度如果训练数据中的真实分布 P 已经固定,那么最小化交叉熵,等价于最小化预测分布和真实分布之间的差异。
从训练的角度,这就足够用了。
这是一个很常见的问题。
均方误差也能算损失,那为什么分类里大家更常用交叉熵?
主要有几个原因。
分类模型通常输出的是概率。
交叉熵直接度量“真实类别的概率有没有被打高”,和任务目标更贴近。
如果模型非常自信,但却把类别预测错了,交叉熵会给出很大的惩罚。
这有助于推动模型更快修正方向。
sigmoid、softmax 搭配非常自然在二分类里,输出层常配 sigmoid。
在多分类里,输出层常配 softmax。
交叉熵和这两类输出形式配合得非常顺畅。
从训练流程看,可以把它理解成下面几步:
所以交叉熵的作用不是“直接给出分类结果”,而是:
模型训练的核心,就是不断让这个损失变小。
交叉熵最典型的使用场景就是分类。
例如:
这类问题通常只需要判断两个类别,常用二分类交叉熵。
例如:
这类问题常用多分类交叉熵。
在像素级分类任务中,每个像素点都要预测属于哪一类。
这类任务通常也会大量使用交叉熵,或者在交叉熵基础上做一些变体。
语言模型每一步都在做“下一个词元预测”。
本质上,这也是一个多分类问题,所以交叉熵同样非常核心。
假设有一个三分类任务,类别分别是:
某个样本的真实标签是“狗”。
如果模型输出:
[猫: 0.1, 狗: 0.8, 鸟: 0.1]
那么交叉熵会比较小,因为真实类别“狗”的概率是 0.8。
如果模型输出:
[猫: 0.7, 狗: 0.2, 鸟: 0.1]
那么交叉熵会比较大,因为真实类别“狗”的概率只有 0.2。
所以交叉熵不会只看“猜没猜对”,它还会看:
这点非常重要。
因为一个模型即使分类结果相同,概率质量不同,训练效果也会不同。
先用最基础的 Python + NumPy 实现一次。
import numpy as np
def binary_cross_entropy(y_true, y_pred, eps=1e-12):
y_pred = np.clip(y_pred, eps, 1 - eps)
loss = -(y_true * np.log(y_pred) + (1 - y_true) * np.log(1 - y_pred))
return np.mean(loss)
y_true = np.array([1, 0, 1, 1], dtype=np.float32)
y_pred = np.array([0.9, 0.2, 0.8, 0.6], dtype=np.float32)
loss = binary_cross_entropy(y_true, y_pred)
print(loss)
这里有一个关键点:
np.clip 用来避免 log(0)因为:
log(0)
是没有定义的,数值上会出问题。
所以实际实现里通常都会做一个很小的截断保护。
下面用 one-hot 标签做一个简单版本。
import numpy as np
def categorical_cross_entropy(y_true, y_pred, eps=1e-12):
y_pred = np.clip(y_pred, eps, 1 - eps)
loss = -np.sum(y_true * np.log(y_pred), axis=1)
return np.mean(loss)
y_true = np.array([
[1, 0, 0],
[0, 1, 0],
[0, 0, 1]
], dtype=np.float32)
y_pred = np.array([
[0.8, 0.1, 0.1],
[0.2, 0.7, 0.1],
[0.1, 0.2, 0.7]
], dtype=np.float32)
loss = categorical_cross_entropy(y_true, y_pred)
print(loss)
如果你已经知道每个样本真实类别的索引,也可以只取真实类别那一列的概率来计算。
在实际深度学习项目里,更常见的是直接用框架内置实现。
BCELoss 或 BCEWithLogitsLossimport torch
import torch.nn as nn
y_true = torch.tensor([1., 0., 1., 1.])
y_pred = torch.tensor([0.9, 0.2, 0.8, 0.6])
criterion = nn.BCELoss()
loss = criterion(y_pred, y_true)
print(loss.item())
不过更常见、更稳妥的写法是:
import torch
import torch.nn as nn
logits = torch.tensor([2.2, -1.4, 1.6, 0.7])
y_true = torch.tensor([1., 0., 1., 1.])
criterion = nn.BCEWithLogitsLoss()
loss = criterion(logits, y_true)
print(loss.item())
为什么很多人更推荐 BCEWithLogitsLoss?
因为它把:
sigmoid合在了一起,数值稳定性通常更好。
CrossEntropyLossimport torch
import torch.nn as nn
logits = torch.tensor([
[2.5, 0.3, 0.2],
[0.1, 1.8, 0.4],
[0.2, 0.5, 2.1]
], dtype=torch.float32)
labels = torch.tensor([0, 1, 2], dtype=torch.long)
criterion = nn.CrossEntropyLoss()
loss = criterion(logits, labels)
print(loss.item())
这里有一个非常重要的点:
CrossEntropyLoss 输入的通常是 logitssoftmax 的概率也就是说,很多情况下你不需要自己先写:
softmax(logits)
再传给 CrossEntropyLoss。
直接传原始输出更常见,也更稳定。
softmax 一起出现在多分类任务里,模型最后一层常常会输出一组原始分数,也就是 logits。
这些值本身不是概率。
softmax 的作用是把它们转换成一个概率分布:
pi = exp(zi) / Σ exp(zj)
其中:
zi 是第 i 类的原始分数pi 是第 i 类的预测概率然后交叉熵会根据真实标签去衡量这个概率分布是否合理。
所以这套组合的逻辑是:
softmax 把分数转成概率0 或 1因为这会带来对数计算问题,也容易导致数值不稳定。
实际实现中通常会做截断,或者直接使用框架封装好的损失函数。
不同框架对输入格式要求不同。
例如 PyTorch 的 CrossEntropyLoss 通常要求类别索引,而不是 one-hot 编码。
如果某些类别样本特别少,模型可能更偏向多数类。
这时可以考虑:
训练时交叉熵常常很重要,但评估模型时还需要结合任务本身看:
不同任务关注点可能不同。
下面给一个非常简化的 PyTorch 多分类训练示例:
import torch
import torch.nn as nn
import torch.optim as optim
model = nn.Linear(10, 3)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-3)
x = torch.randn(8, 10)
y = torch.tensor([0, 1, 2, 1, 0, 2, 1, 0], dtype=torch.long)
logits = model(x)
loss = criterion(logits, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(loss.item())
这个例子里,交叉熵承担的角色非常清楚: