2018-11-04
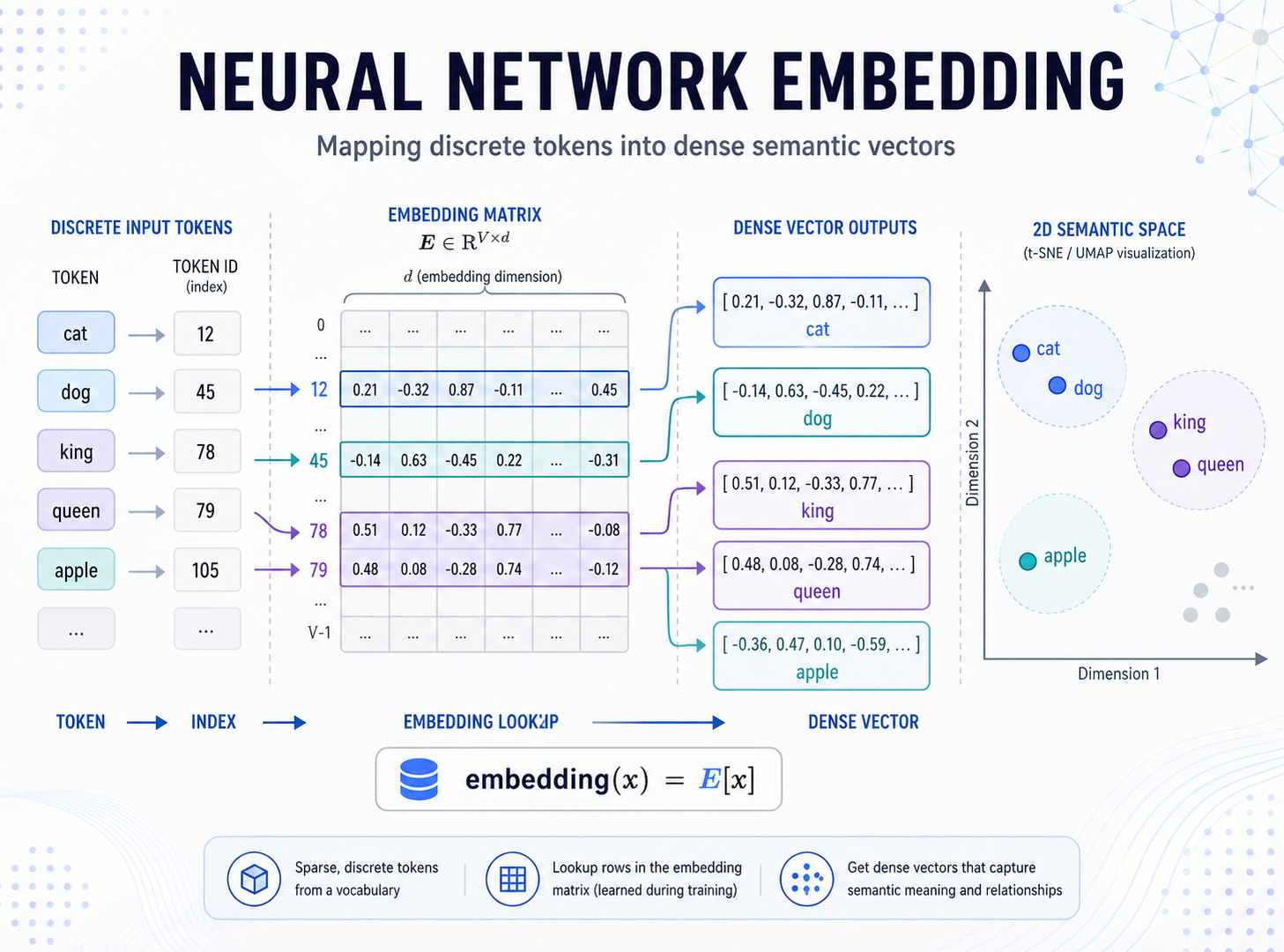
Embedding 是深度学习里非常常见的一层,尤其是在自然语言处理、推荐系统、搜索、广告、用户画像这些场景里,几乎到处都能看到它。
它看起来像一个普通的查表操作:输入一个整数 ID,输出一个向量。
但这个“查表”背后很有意思。Embedding 层通常有两个核心作用:
假设我们有一个很小的词表:
我 从 哪 里 来 要 到 何 处 去
可以给每个字分配一个编号:
我 -> 0
从 -> 1
哪 -> 2
里 -> 3
来 -> 4
要 -> 5
到 -> 6
何 -> 7
处 -> 8
去 -> 9
那么一句话可以表示成整数序列:
我 从 哪 里 来
对应:
[0, 1, 2, 3, 4]
整数编号很紧凑,但它本身没有表达语义。编号 0 和编号 1 并不代表“我”和“从”更相似,只是刚好编号相邻。
如果用 one-hot 表示,每个字会变成一个长度等于词表大小的向量。
例如词表大小是 10:
我 -> [1, 0, 0, 0, 0, 0, 0, 0, 0, 0]
从 -> [0, 1, 0, 0, 0, 0, 0, 0, 0, 0]
哪 -> [0, 0, 1, 0, 0, 0, 0, 0, 0, 0]
这种表示有一个明显特点:非常稀疏。
词表只有 10 个词还好,如果词表有几十万甚至更多,每个 token 的 one-hot 向量就会非常长,而且里面几乎全是 0。
Embedding 最直观的作用,就是把高维稀疏的 one-hot 向量变成低维稠密向量。

假设词表大小是 10000,如果使用 one-hot,每个词就是一个 10000 维向量。
如果使用 Embedding,可以把每个词映射成一个更短的向量,比如:
我 -> [0.12, -0.35, 0.88, 0.04]
从 -> [-0.21, 0.19, 0.33, -0.72]
哪 -> [0.45, 0.08, -0.11, 0.27]
这样每个词从 10000 维变成了 4 维。
当然,真实任务里维度可能是几十、几百或更高,具体要看数据规模和任务复杂度。
Embedding 层本质上维护了一个矩阵:
Embedding Matrix: vocab_size × embedding_dim
例如:
词表大小 vocab_size = 10000
向量维度 embedding_dim = 128
那么 Embedding 矩阵就是:
10000 × 128
每一行对应一个 token 的向量。
当输入 token ID 时,Embedding 层就取出对应那一行。
假设 Embedding 矩阵是:
E =
[
[0.10, 0.20, 0.30],
[0.40, 0.50, 0.60],
[0.70, 0.80, 0.90]
]
如果输入 ID 是 1,那么输出就是矩阵第 1 行:
[0.40, 0.50, 0.60]
如果输入 ID 序列是:
[2, 0, 1]
输出就是:
[
[0.70, 0.80, 0.90],
[0.10, 0.20, 0.30],
[0.40, 0.50, 0.60]
]
从实现角度看,Embedding 是查表。
从训练角度看,Embedding 矩阵是模型参数,会随着反向传播不断更新。
如果一个 token 的 one-hot 是:
[0, 1, 0]
Embedding 矩阵是:
[
[0.10, 0.20, 0.30],
[0.40, 0.50, 0.60],
[0.70, 0.80, 0.90]
]
那么:
[0, 1, 0] × E = [0.40, 0.50, 0.60]
结果正好是第 1 行。
所以 Embedding 可以理解为:
不用真的构造巨大的 one-hot,而是直接根据 ID 取矩阵中的一行
这就是它高效的地方。
用 NumPy 可以演示一下:
import numpy as np
embedding_matrix = np.array([
[0.10, 0.20, 0.30],
[0.40, 0.50, 0.60],
[0.70, 0.80, 0.90],
])
one_hot = np.array([0, 1, 0])
print(one_hot @ embedding_matrix)
print(embedding_matrix[1])
两个输出是一样的。
Embedding 不只是降维。
如果只是把高维变低维,那它还不够有趣。Embedding 更重要的能力是:经过训练后,向量可以表达对象之间的关系。
比如在自然语言里:
猫、狗、兔子
这些词可能都和动物相关。
而:
汽车、公交、火车
这些词可能都和交通工具相关。
经过合适的训练后,它们在向量空间中的位置可能会更接近。

这就是 Embedding 的第二个核心作用:让相似的对象具有相似的向量表示。
所谓“相似”,不一定只来自字面含义,也可以来自行为模式或上下文。
在推荐系统里:
在 NLP 里:
常用方法是余弦相似度:
cosine(a, b) = (a · b) / (||a|| × ||b||)
其中:
a · b 是两个向量的点积||a|| 和 ||b|| 是向量长度用 Python 写一个简单版本:
import numpy as np
def cosine_similarity(a, b):
a = np.asarray(a)
b = np.asarray(b)
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
cat = [0.2, 0.8, 0.1]
dog = [0.3, 0.7, 0.2]
car = [0.9, 0.1, 0.4]
print(cosine_similarity(cat, dog))
print(cosine_similarity(cat, car))
通常来说,如果 cat 和 dog 的语义更接近,它们的余弦相似度应该更高。
PyTorch 中可以使用 nn.Embedding。
import torch
import torch.nn as nn
embedding = nn.Embedding(
num_embeddings=10,
embedding_dim=4
)
token_ids = torch.tensor([0, 1, 2, 3])
output = embedding(token_ids)
print(output.shape)
print(output)
输出形状是:
torch.Size([4, 4])
含义是:输入 4 个 token ID,每个 ID 被映射成 4 维向量。
如果输入是一个 batch:
token_ids = torch.tensor([
[0, 1, 2],
[3, 4, 5],
])
output = embedding(token_ids)
print(output.shape)
输出形状是:
torch.Size([2, 3, 4])
含义是:
batch_size = 2
sequence_length = 3
embedding_dim = 4
会。
nn.Embedding 里的权重就是一个普通的可训练参数:
print(embedding.weight.shape)
print(embedding.weight.requires_grad)
如果参与模型训练,Embedding 矩阵会随着损失函数反向传播不断更新。
一个简单文本分类结构可以这样写:
import torch
import torch.nn as nn
class TextClassifier(nn.Module):
def __init__(self, vocab_size, embedding_dim, num_classes):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.fc = nn.Linear(embedding_dim, num_classes)
def forward(self, token_ids):
x = self.embedding(token_ids)
x = x.mean(dim=1)
logits = self.fc(x)
return logits
model = TextClassifier(
vocab_size=10000,
embedding_dim=128,
num_classes=2
)
batch_token_ids = torch.randint(0, 10000, (32, 20))
logits = model(batch_token_ids)
print(logits.shape)
这里的逻辑是:
token ID -> Embedding -> 平均池化 -> 分类层
这只是一个很简化的例子,但足够说明 Embedding 如何进入神经网络。
文本序列长度通常不一样。为了组成 batch,经常需要补齐。
比如:
[12, 35, 8]
[9, 4]
补齐后:
[12, 35, 8]
[9, 4, 0]
这里可以约定 0 是 padding。
PyTorch 可以这样设置:
embedding = nn.Embedding(
num_embeddings=10000,
embedding_dim=128,
padding_idx=0
)
padding_idx=0 表示 ID 为 0 的向量不参与梯度更新,适合当作补齐符号。
Keras 中也有 Embedding 层:
import tensorflow as tf
from tensorflow.keras import layers, models
model = models.Sequential([
layers.Embedding(
input_dim=10000,
output_dim=128,
mask_zero=True
),
layers.GlobalAveragePooling1D(),
layers.Dense(2, activation="softmax")
])
model.summary()
参数含义:
input_dim:词表大小output_dim:Embedding 向量维度mask_zero:是否把 0 当作 padding输入形状可以是:
batch_size × sequence_length
输出形状会变成:
batch_size × sequence_length × output_dim
Embedding 不只用于文本。
推荐系统里经常会把用户 ID、商品 ID、类别 ID、城市 ID 等离散特征都变成向量。
比如:
import torch
import torch.nn as nn
class SimpleRecModel(nn.Module):
def __init__(self, num_users, num_items, embedding_dim):
super().__init__()
self.user_embedding = nn.Embedding(num_users, embedding_dim)
self.item_embedding = nn.Embedding(num_items, embedding_dim)
def forward(self, user_ids, item_ids):
user_vec = self.user_embedding(user_ids)
item_vec = self.item_embedding(item_ids)
score = (user_vec * item_vec).sum(dim=1)
return score
model = SimpleRecModel(
num_users=100000,
num_items=50000,
embedding_dim=64
)
user_ids = torch.tensor([1, 2, 3])
item_ids = torch.tensor([10, 20, 30])
scores = model(user_ids, item_ids)
print(scores)
这个模型非常简化,但表达了推荐系统里常见的思想:
用户向量 · 商品向量 = 匹配分数
如果用户和商品越匹配,点积得分就应该越高。
普通离散特征如果直接用整数表示,模型可能误以为编号之间存在大小关系。
比如:
北京 -> 1
上海 -> 2
广州 -> 3
这里的 3 并不比 1 更大,编号只是类别标识。
One-hot 可以避免错误的大小关系,但维度太高、太稀疏。
Embedding 则折中得很好:
类别 ID -> 低维向量
它既避免了整数 ID 的伪大小关系,又避免了 one-hot 的高维稀疏问题。
Embedding 维度没有固定答案。
维度太小,表达能力可能不够。
维度太大,参数量会增加,也更容易过拟合。
参数量可以简单估算:
参数量 = vocab_size × embedding_dim
比如:
vocab_size = 100000
embedding_dim = 128
参数量就是:
100000 × 128 = 12800000
也就是一千多万个参数。
所以 Embedding 维度不是越大越好,要结合数据规模、任务复杂度和资源情况来定。
Embedding 可以随机初始化,也可以使用预训练向量。
随机初始化的好处是简单,模型会在当前任务中自己学习。
预训练向量的好处是已经包含一些通用语义信息,适合数据较少或希望利用外部语料的场景。
在 PyTorch 中,可以把已有矩阵加载成 Embedding:
import torch
import torch.nn as nn
pretrained_weight = torch.randn(10000, 128)
embedding = nn.Embedding.from_pretrained(
pretrained_weight,
freeze=False
)
freeze=False 表示继续训练这个 Embedding。
如果不希望更新:
embedding = nn.Embedding.from_pretrained(
pretrained_weight,
freeze=True
)
Embedding 的应用非常广。
在 NLP 里:
在推荐系统里:
在搜索和广告里:
在图学习里:
一句话概括:
只要对象能被编号,又希望模型学习对象之间的关系,就可以考虑 Embedding。
Embedding 不是简单压缩。
它不只是把大向量变成小向量,更重要的是通过训练学到有意义的表示。
Embedding 也不是天然有语义。
刚初始化时,它通常只是随机向量。只有经过任务训练,向量空间才会逐渐形成有用的结构。
整数 ID 不能直接当连续数值喂给模型。
比如商品 ID 为 100 和 101,不代表这两个商品一定相似。ID 只是编号,不是数值大小。
Embedding 维度不是越大越好。
维度越大,参数越多,训练成本和过拟合风险也会增加。
Embedding 层可以看成一个可训练的查表矩阵。
输入是整数 ID,输出是低维稠密向量。
它的两个核心作用是:
从数学上看,Embedding 查表和 one-hot 乘 Embedding 矩阵是等价的。但在实现上,直接查表更高效,不需要真的构造巨大的 one-hot 向量。
在实际项目中,Embedding 不只属于 NLP。用户、商品、城市、类别、广告、节点,只要是离散 ID,都可以通过 Embedding 变成可训练的向量表示。
理解 Embedding 的关键不是背 API,而是记住这一点:
Embedding 是把离散对象放进连续向量空间,让模型能学习它们之间的关系。