2019-01-15
CNN,也就是卷积神经网络,前向传播比较容易理解:输入图像经过卷积、激活、池化、全连接,最后得到预测结果。
反向传播看起来更绕,但本质只有一句话:
从损失函数开始,沿着前向计算图反方向,用链式法则逐层计算梯度。
一个简化版 CNN 可以看成下面几部分:
输入图像 -> 卷积层 -> 激活层 -> 池化层 -> 全连接层 -> 损失函数
前向传播负责计算预测值,反向传播负责计算每个参数应该怎么更新。

训练神经网络的目标是让损失函数变小。参数更新通常写成:
w = w - η × ∂L/∂w
其中:
w 是参数η 是学习率L 是损失函数∂L/∂w 是损失对参数的梯度所以反向传播的核心任务就是计算梯度。
假设有一个简单计算链:
x -> z -> y -> L
也就是:
z = f(x)
y = g(z)
L = h(y)
如果要求 L 对 x 的导数,根据链式法则:
∂L/∂x = ∂L/∂y × ∂y/∂z × ∂z/∂x
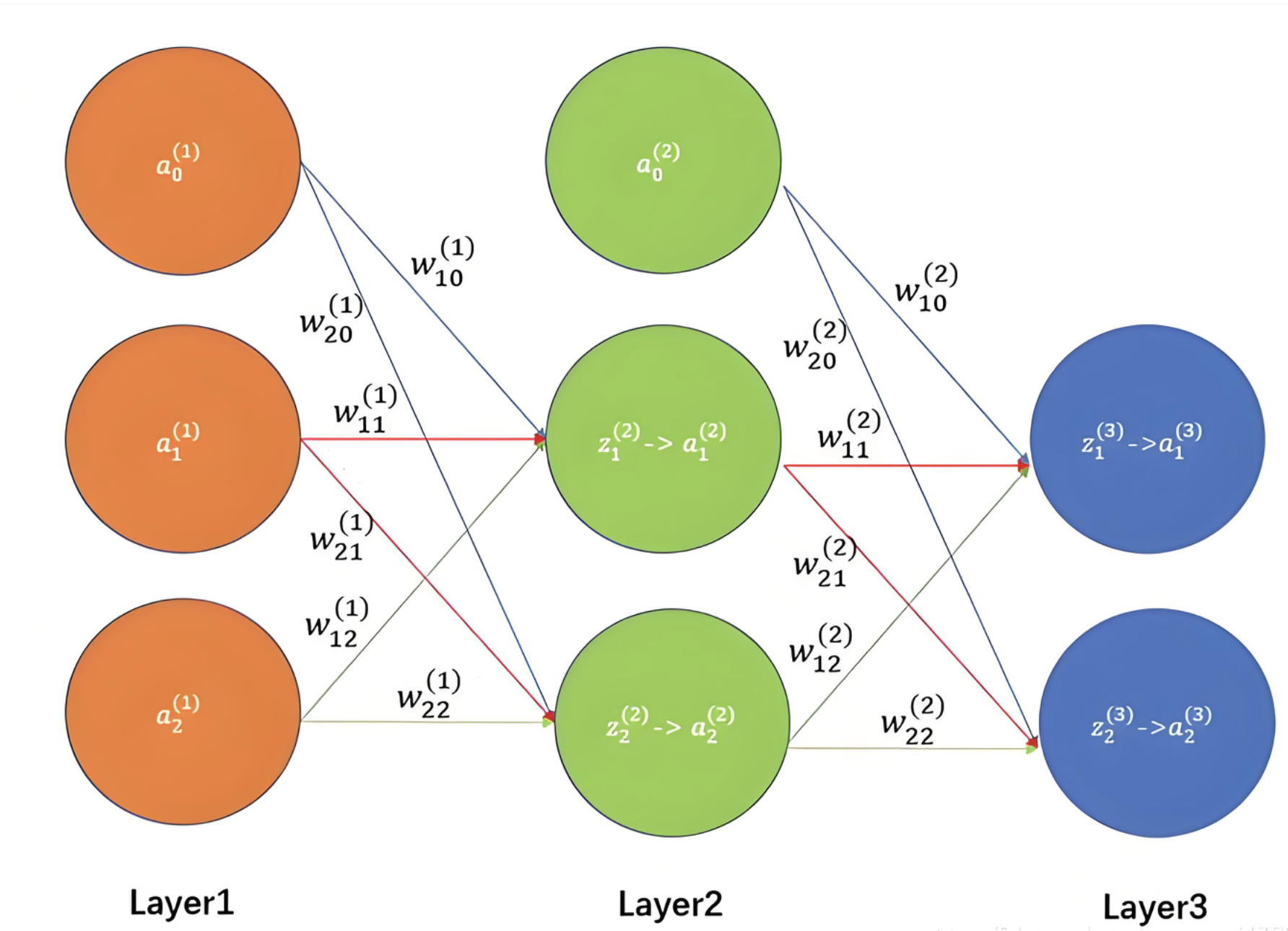
神经网络就是很多这种计算链组合起来的复杂计算图。
每一层只需要做两件事:
1. 接收来自后一层的上游梯度
2. 乘上本层的局部梯度,得到传给前一层的梯度
这就是反向传播。
先从最容易推导的全连接层开始。
全连接层的前向传播可以写成:
z = Wx + b
其中:
x 是输入W 是权重矩阵b 是偏置z 是输出如果只看一个神经元:
z = w1x1 + w2x2 + ... + wnxn + b
这个过程就是加权求和。
假设后一层传回来的梯度是:
δ = ∂L/∂z
那么全连接层的参数梯度是:
∂L/∂W = δ x^T
∂L/∂b = δ
传给前一层输入的梯度是:
∂L/∂x = W^T δ
直观理解:
如果是一个 batch,梯度通常会对 batch 内样本求和或求平均。
CNN 中常见激活函数是 ReLU:
ReLU(x) = max(0, x)
它的导数可以写成:
ReLU'(x) =
1, x > 0
0, x <= 0
ReLU 的反向传播很像一个门:
假设上游梯度是 δ,那么 ReLU 传给前一层的梯度是:
δ_prev = δ × ReLU'(x)
也就是:
δ_prev = δ, x > 0
δ_prev = 0, x <= 0
这就是为什么反向传播时通常要保存前向传播中的中间结果。
没有前向输入 x,就不知道哪些位置应该让梯度通过。
以分类任务常见的 softmax + 交叉熵为例。
softmax 把输出变成概率:
p_i = e^(z_i) / Σe^(z_j)
交叉熵损失:
L = -Σ y_i log(p_i)
其中:
y_i 是真实标签的 one-hot 表示p_i 是预测概率softmax 和交叉熵组合后,梯度形式非常简洁:
∂L/∂z_i = p_i - y_i
这表示:
损失函数是反向传播的起点。
卷积层的前向传播可以理解为:卷积核在输入图像上滑动,每到一个位置就和局部区域做乘加运算。
简化写法:
y = conv(x, k) + b
其中:
x 是输入特征图k 是卷积核b 是偏置y 是输出特征图一个卷积核会提取一种局部模式。多个卷积核会产生多个输出通道。
卷积层反向传播主要要求三个东西:
∂L/∂k:卷积核梯度
∂L/∂b:偏置梯度
∂L/∂x:传给前一层的输入梯度
其中卷积核梯度最好理解。
前向传播时,某个输出位置由一个输入窗口和卷积核相乘得到。反向传播时,这个输出位置的上游梯度会乘以对应输入窗口,对卷积核产生贡献。

可以用一句话概括:
卷积核梯度 = 所有位置的 输入窗口 × 对应上游梯度 的累加
偏置梯度更简单:
偏置梯度 = 所有输出位置上游梯度的累加
输入梯度则可以理解为:每个输入像素影响了哪些输出位置,就从这些输出位置把梯度累加回来。
池化层没有可训练参数,但它也需要把梯度传回前一层。
常见池化有两类:
Max Pooling 前向传播时会取窗口里的最大值。
反向传播时,梯度只传给前向传播时那个最大值所在的位置。
例如:
输入窗口:
1 3
2 4
Max Pooling 输出是:
4
如果上游梯度是 δ,那么反向传播结果是:
0 0
0 δ
因为只有 4 这个位置真正参与了输出。
Average Pooling 前向传播时求平均。
反向传播时,梯度平均分给窗口里的每个位置。
如果窗口大小是 2 × 2,上游梯度是 δ,则每个位置得到:
δ / 4
用 NumPy 可以很直观地看 ReLU 的梯度门控。
import numpy as np
def relu_forward(x):
return np.maximum(0, x)
def relu_backward(dout, x):
dx = dout.copy()
dx[x <= 0] = 0
return dx
x = np.array([-2.0, -0.5, 0.0, 1.0, 3.0])
dout = np.ones_like(x)
y = relu_forward(x)
dx = relu_backward(dout, x)
print("forward:", y)
print("backward:", dx)
输出:
forward: [0. 0. 0. 1. 3.]
backward: [0. 0. 0. 1. 1.]
负数位置前向输出为 0,反向梯度也被截断。
下面写一个极简全连接层。
import numpy as np
class Linear:
def __init__(self, in_features, out_features):
self.W = np.random.randn(out_features, in_features) * 0.01
self.b = np.zeros(out_features)
self.x = None
self.dW = None
self.db = None
def forward(self, x):
self.x = x
return x @ self.W.T + self.b
def backward(self, dout):
self.dW = dout.T @ self.x
self.db = dout.sum(axis=0)
dx = dout @ self.W
return dx
layer = Linear(in_features=3, out_features=2)
x = np.array([
[1.0, 2.0, 3.0],
[4.0, 5.0, 6.0],
])
out = layer.forward(x)
dout = np.ones_like(out)
dx = layer.backward(dout)
print("out:", out)
print("dW:", layer.dW)
print("db:", layer.db)
print("dx:", dx)
这里的关键是:
dW = dout.T @ x
db = sum(dout)
dx = dout @ W
这正是全连接层反向传播的矩阵形式。
实际开发中,我们通常不手写反向传播,而是交给框架自动求导。
下面是一个小型 CNN:
import torch
import torch.nn as nn
class SmallCNN(nn.Module):
def __init__(self):
super().__init__()
self.net = nn.Sequential(
nn.Conv2d(1, 4, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(4 * 14 * 14, 10)
)
def forward(self, x):
return self.net(x)
model = SmallCNN()
x = torch.randn(8, 1, 28, 28)
y = torch.randint(0, 10, (8,))
criterion = nn.CrossEntropyLoss()
logits = model(x)
loss = criterion(logits, y)
loss.backward()
for name, param in model.named_parameters():
print(name, param.grad.shape)
loss.backward() 会自动沿计算图反向传播,把每个参数的梯度放到 param.grad 里。
然后优化器根据梯度更新参数:
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
optimizer.zero_grad()
logits = model(x)
loss = criterion(logits, y)
loss.backward()
optimizer.step()
训练循环通常就是这几步:
清空梯度 -> 前向传播 -> 计算损失 -> 反向传播 -> 更新参数
PyTorch 中梯度默认是累加的。
如果不执行:
optimizer.zero_grad()
多次 backward() 的梯度会加在一起。
这在某些梯度累积场景有用,但普通训练中通常不是我们想要的。
所以标准训练步骤里会先清空梯度。
CNN 中会被更新的是可训练参数,比如:
不会被更新的是无参数层,比如:
但无参数层仍然参与反向传播,因为它们要负责把梯度传回前面的层。
反向传播不是“从输出层重新算一遍前向”。
它是沿着计算图反方向,根据链式法则计算每个中间变量和参数的梯度。
池化层没有参数,但不是没有反向传播。
Max Pooling 要把梯度传给最大值位置,Average Pooling 要把梯度平均分配回窗口。
ReLU 很简单,但会截断负区间梯度。
如果大量神经元长期落在负区间,可能出现梯度无法通过的问题。
卷积层反向传播不是玄学。
卷积核梯度来自输入窗口和上游梯度的乘积累加,输入梯度来自相关输出位置的梯度回传。
CNN 反向传播的核心是链式法则。
前向传播时,每一层保存必要的中间结果;反向传播时,每一层接收上游梯度,结合本层局部导数,计算参数梯度和传给前一层的梯度。
可以简单记成:
全连接层:根据输入和上游梯度计算 W、b 的梯度
ReLU:正区间放行梯度,负区间截断梯度
卷积层:输入窗口和上游梯度共同决定卷积核梯度
池化层:Max Pool 传给最大值位置,Avg Pool 平均分配
损失函数:提供反向传播的起点
理解这些之后,再看 PyTorch 里的 loss.backward() 就不会觉得神秘了。
框架帮我们做了自动求导,但背后的逻辑仍然是:局部梯度乘以上游梯度,一层一层传回去。