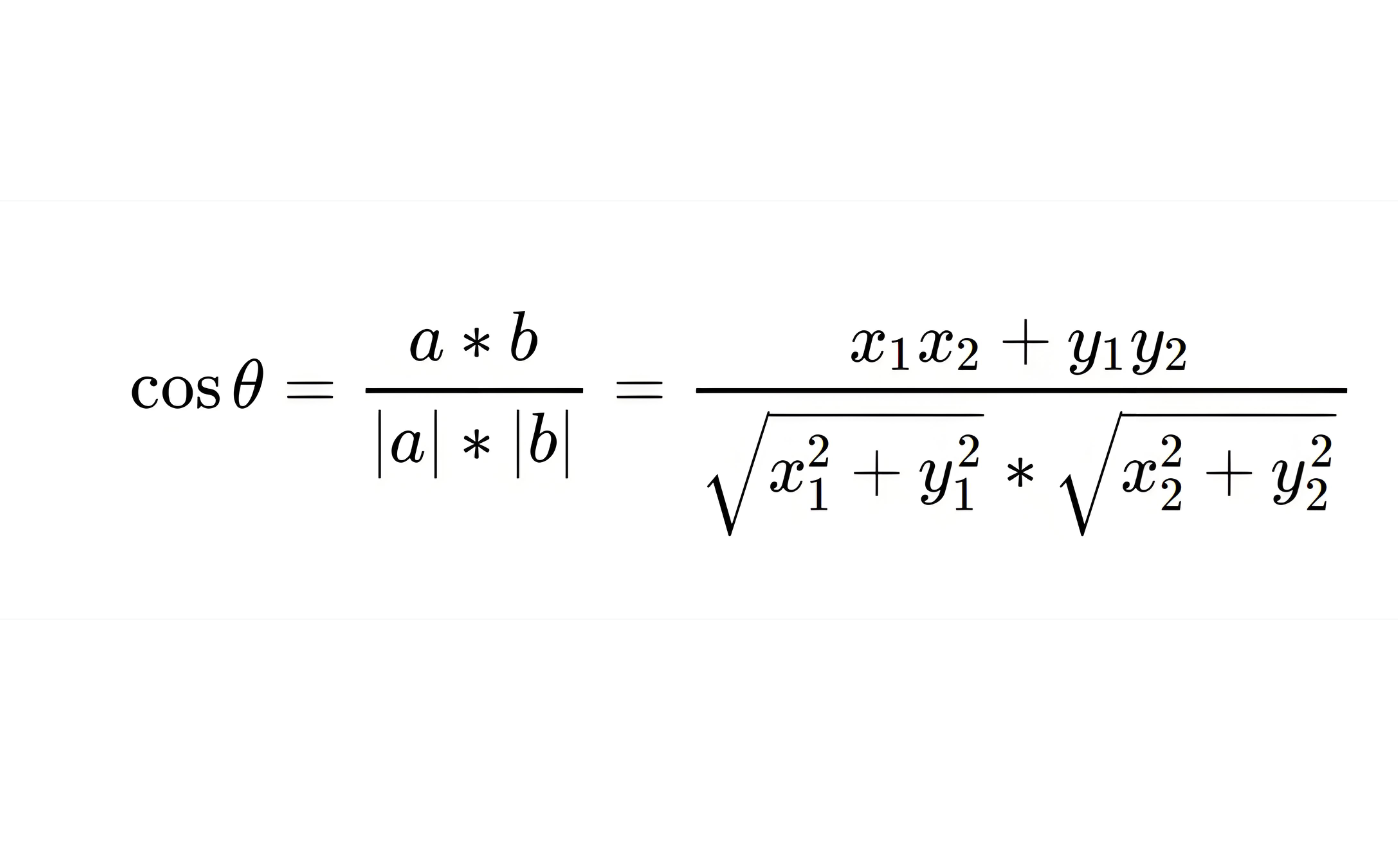
2019-11-02
两句话到底像不像,机器没法像人一样先“感觉一下”。比较常见的做法是:先把文本变成向量,再比较两个向量的方向。 余弦相似度做的就是这件事。它不太关心向量有多长,更关心两个向量是不是朝着差不多的方向走。方向越接近,相似度越高。
余弦相似度来自向量夹角。两个向量的夹角越小,说明它们的方向越接近。
公式长这样:
cos(A, B) = (A · B) / (|A| × |B|)
其中:
A · B 是两个向量的点积|A| 和 |B| 是两个向量的模长1,说明越相似0,说明关系比较弱
这套思路放到文本里也能用:先分词,再把每个词映射到向量里的一个位置,最后算两个向量的余弦值。
拿两段文本来试试:
A:中国工商银行北京分部北京支行
B:中国招商银行广西分部桂林支行
分词后可以得到:
A:中国 / 工商银行 / 北京 / 分部 / 北京 / 支行
B:中国 / 招商银行 / 广西 / 分部 / 桂林 / 支行
把两段文本里出现过的词合并成一个局部词表:
[中国, 工商银行, 招商银行, 北京, 广西, 支行, 桂林, 分部]
接着统计每个词出现的次数:
A = [1, 1, 0, 2, 0, 1, 0, 1]
B = [1, 0, 1, 0, 1, 1, 1, 1]

这就是一个很朴素的词袋模型。词袋模型不关心词语顺序,只看这个词有没有出现、出现了几次。
用这两个向量计算余弦相似度:
import math
a = [1, 1, 0, 2, 0, 1, 0, 1]
b = [1, 0, 1, 0, 1, 1, 1, 1]
dot = sum(x * y for x, y in zip(a, b))
norm_a = math.sqrt(sum(x * x for x in a))
norm_b = math.sqrt(sum(y * y for y in b))
score = dot / (norm_a * norm_b)
print(round(score, 3))
输出大约是:
0.433
这个值不算特别高,因为两段文本里只有“中国、分部、支行”这些词重合,核心银行名和地区名并不一样。
词袋模型很直观,但它有个明显问题:只要词频一样,它就认为这些词的贡献一样。
比如:
中国招商银行广西分部桂林支行
中国招商银行广西分部南宁支行
如果只在这两句话内部建词表,“桂林”和“南宁”都只是出现一次的地区词。对于朴素词袋来说,它们差不多就是两个不同的占位符。
但在业务里,“桂林”和“南宁”可能很关键。尤其做机构名、地址、门店、物流网点这类文本匹配时,一个地名的差异往往不能被轻轻带过。
这就轮到 TF-IDF 上场了。
TF-IDF 可以理解成两股力量的合体:
TF:词在当前文本里出现得多不多
IDF:词在整个语料里稀不稀有
一个常用写法是:
TF-IDF = TF × IDF
IDF 的基础思想是:
IDF = log(语料文本总数 / 包含该词的文本数)
实际写代码时,经常会做平滑,避免分母为零,也让权重更稳定:
IDF = log((N + 1) / (DF + 1)) + 1
假如“中国”“支行”这类词到处都能见到,它们的 IDF 就会偏低;“桂林”“南宁”这种更有区分度的词,IDF 会更高。于是相似度计算时,关键地名会更有存在感。

先来一个不依赖第三方库的简洁版本。为了让重点更清楚,这里直接给分词结果:
from collections import Counter
from math import sqrt
def bow_cosine(tokens_a, tokens_b):
counter_a = Counter(tokens_a)
counter_b = Counter(tokens_b)
vocab = sorted(set(counter_a) | set(counter_b))
vec_a = [counter_a[word] for word in vocab]
vec_b = [counter_b[word] for word in vocab]
dot = sum(x * y for x, y in zip(vec_a, vec_b))
norm_a = sqrt(sum(x * x for x in vec_a))
norm_b = sqrt(sum(y * y for y in vec_b))
if norm_a == 0 or norm_b == 0:
return 0.0
return dot / (norm_a * norm_b)
text_a = ["中国", "工商银行", "北京", "分部", "北京", "支行"]
text_b = ["中国", "招商银行", "广西", "分部", "桂林", "支行"]
print(round(bow_cosine(text_a, text_b), 3))
这段代码适合解释原理,也适合做小规模实验。它的核心很简单:两个 Counter,一个统一词表,两条同维度向量。
中文文本一般需要先分词。可以把 jieba.lcut 交给 TfidfVectorizer 当 tokenizer:
import jieba
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
texts = [
"中国工商银行北京分部北京支行",
"中国招商银行广西分部桂林支行",
"中国招商银行广西分部南宁支行",
]
vectorizer = TfidfVectorizer(
tokenizer=jieba.lcut,
token_pattern=None
)
tfidf = vectorizer.fit_transform(texts)
similarity = cosine_similarity(tfidf)
print(vectorizer.get_feature_names_out())
print(similarity.round(3))
similarity 是一个相似度矩阵。第 i 行第 j 列,就是第 i 条文本和第 j 条文本的余弦相似度。
如果你只想看两句话:
score = cosine_similarity(tfidf[0], tfidf[1])[0][0]
print(round(score, 3))
这种写法比手写词袋更适合放到搜索、去重、相似问匹配这类场景里。
jieba.analyse.extract_tags 也能直接给关键词和权重,快速看一段文本里哪些词更重要:
import jieba.analyse
sentence = "中国招商银行广西分部桂林支行"
keywords = jieba.analyse.extract_tags(
sentence,
topK=10,
withWeight=True
)
for word, weight in keywords:
print(word, round(weight, 3))
这个结果可以拿来做关键词展示,也可以配合自己的业务词典继续加工。
余弦相似度和 TF-IDF 这一套很适合做偏“字面相似”的任务:
它的优点是轻、快、容易解释。你能清楚看到每个词怎么进入向量,也能看到 TF-IDF 怎么改变权重。
词袋和 TF-IDF 也有边界。
它们不理解词序。比如“我喜欢你”和“你喜欢我”,词都差不多,但意思变了。
它们也不天然理解同义词。比如“退款”和“退钱”在语义上很近,但如果语料和分词处理不好,向量里可能就是两个不相干的词。
所以一个实用策略是:
TF-IDF + 余弦相似度:做快速召回和可解释初筛
Embedding / 语义模型:做更深的语义匹配
如果任务更看重语义,而不是字面重合,可以考虑句向量、SimCSE、Sentence-BERT 等方法。它们成本更高,但对“意思相近、字面不同”的文本更友好。
余弦相似度的核心很朴素:把文本变成向量,看两个向量方向像不像。
词袋模型能把分词结果快速转成计数向量,但它不懂词的重要程度。TF-IDF 给词加上权重,让稀有且有区分度的词更有话语权。
真正落到业务里,可以先用 jieba + TfidfVectorizer + cosine_similarity 搭一个轻量版本。效果够用就继续打磨词典和语料;如果字面方法开始吃力,再引入语义向量模型。