
Category
Category Feed
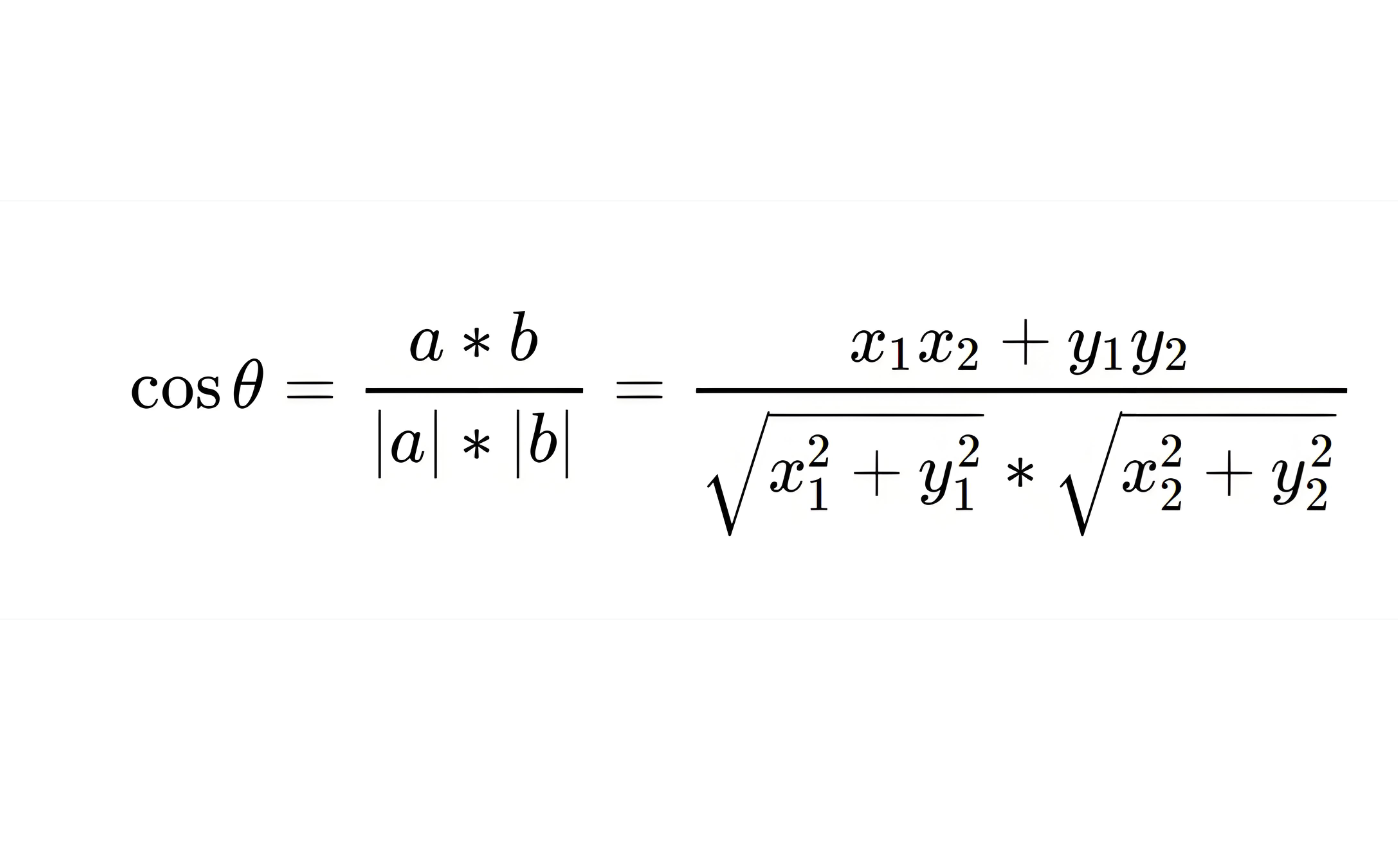
两句话到底像不像,机器没法像人一样先“感觉一下”。比较常见的做法是:先把文本变成向量,再比较两个向量的方向。 余弦相似度做的就是这件事。它不太关心向量有多长,更关心两个向量是不是朝着差不多的方向走。方向越接近,相似度越高。
Read
有些目标检测文章一讲到 `loss` 就开始一串公式劈头盖脸砸下来,看着像懂了,回头一写代码又有点发懵。这个话题其实没必要绕那么远: - 真实标签到底长什么样 - 网络最后吐出了什么 - 这些量分别在逼着模型优化什么
Read
普通卷积很好用,但也很“费”。输入通道多、输出通道多、卷积核又不小的时候,计算量和参数量都会蹭蹭上去。 可分离卷积的思路很妙:既然普通卷积同时做了“空间特征提取”和“通道混合”,那我们能不能把这两件事拆开?先在每个通道里单独看空间,再用 `1×1` 卷积把通道信息混起来。
Read

深度学习里的 Norm 家族很热闹:BN、LN、IN、GN、SN,看名字像一串缩写暗号。 但它们的出发点并不玄乎:网络越深,中间层的数据分布越容易乱跑。分布一乱,后面的层就要一边学习任务,一边适应前面层不断变化的输出,训练自然会变慢、变抖,甚至变得难收敛。
Read
上一篇我们已经聊过 `CosineConv2D` 这种更偏卷积算子层面的新玩法,这一篇换个方向,看几个不用大改骨架、但很有意思的“小招式”。
Read
普通卷积大家都熟:卷积核在图像上滑动,每次取一个局部窗口,和卷积核做对应位置相乘再求和。 `CosineConv2D` 换了一个思路:不要只看点乘结果有多大,而是看输入局部窗口和卷积核方向有多像。
Read

YOLOv3 的损失函数看起来绕,主要是因为它不是只算一个分类误差,而是同时处理四件事:框中心点是否准 、框宽高是否准 、这个位置是否有目标 、目标属于哪个类别
Read