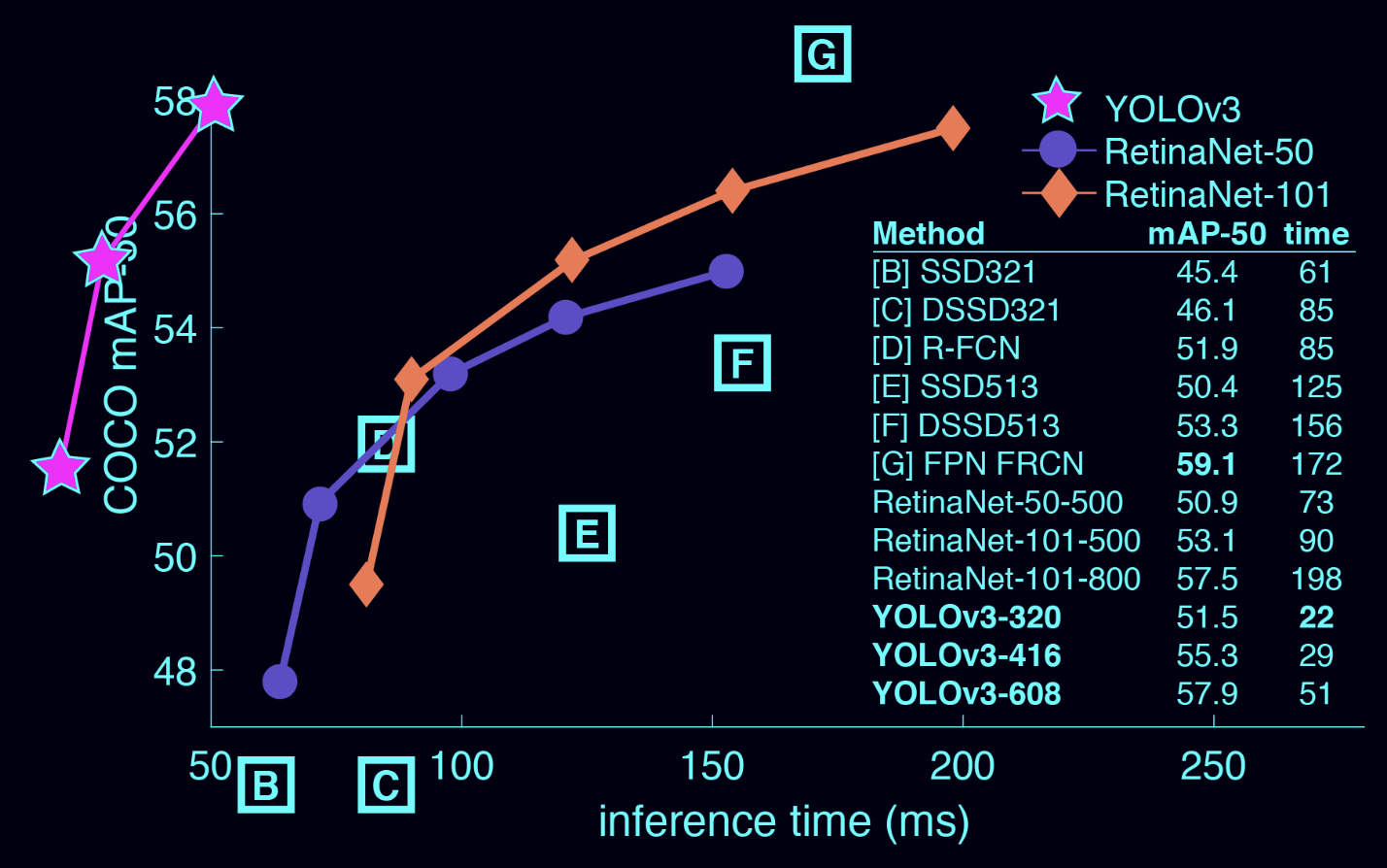
YOLOv3 数据输入详解
YOLOv3 的模型结构很重要,但训练能不能跑起来,第一关往往不是网络,而是数据。 图片怎么读?标注怎么写?框坐标怎么变?anchor 怎么匹配?`y_true` 到底是什么形状?
ReadCategory
Category Feed
YOLOv3 的模型结构很重要,但训练能不能跑起来,第一关往往不是网络,而是数据。 图片怎么读?标注怎么写?框坐标怎么变?anchor 怎么匹配?`y_true` 到底是什么形状?
Read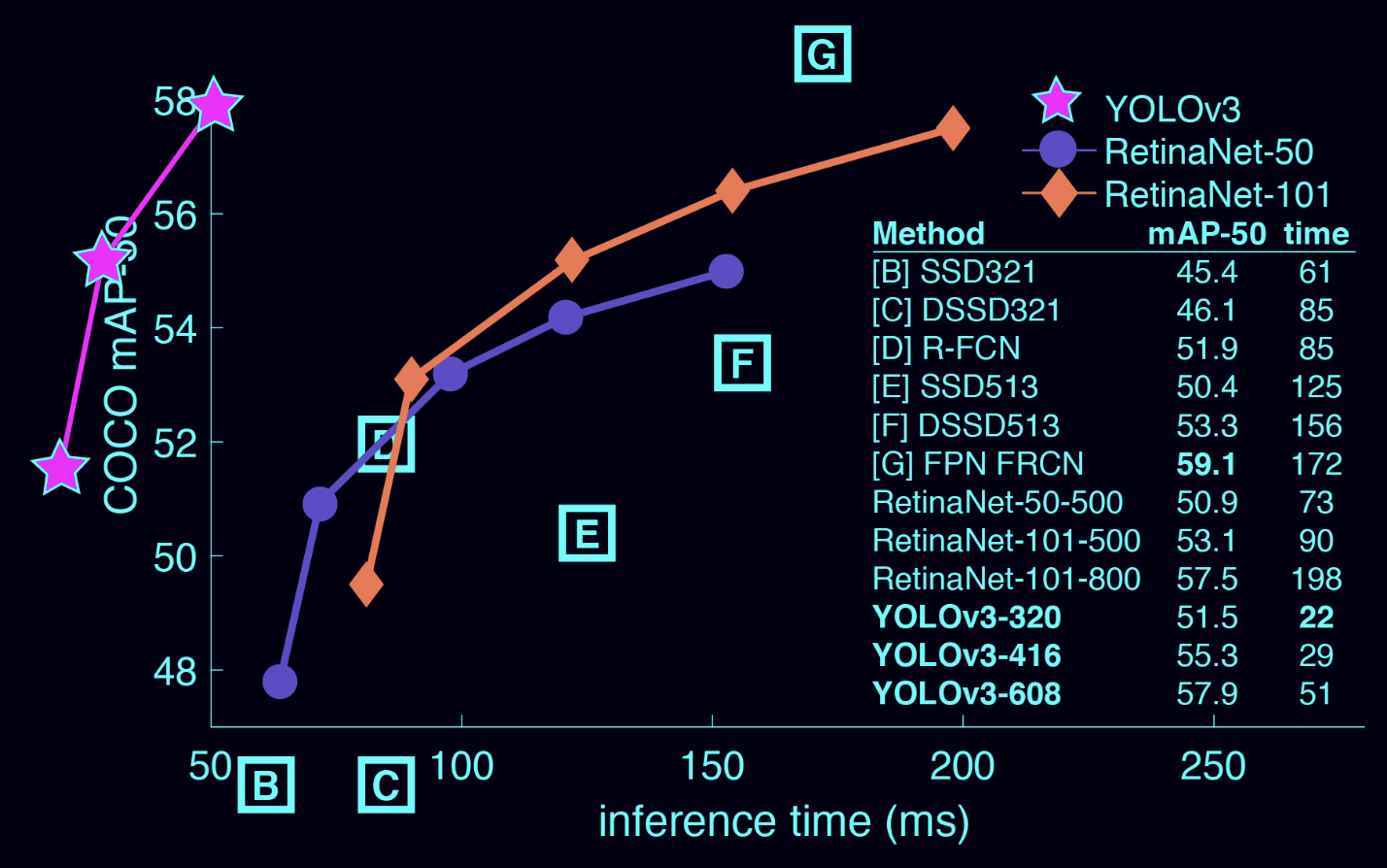
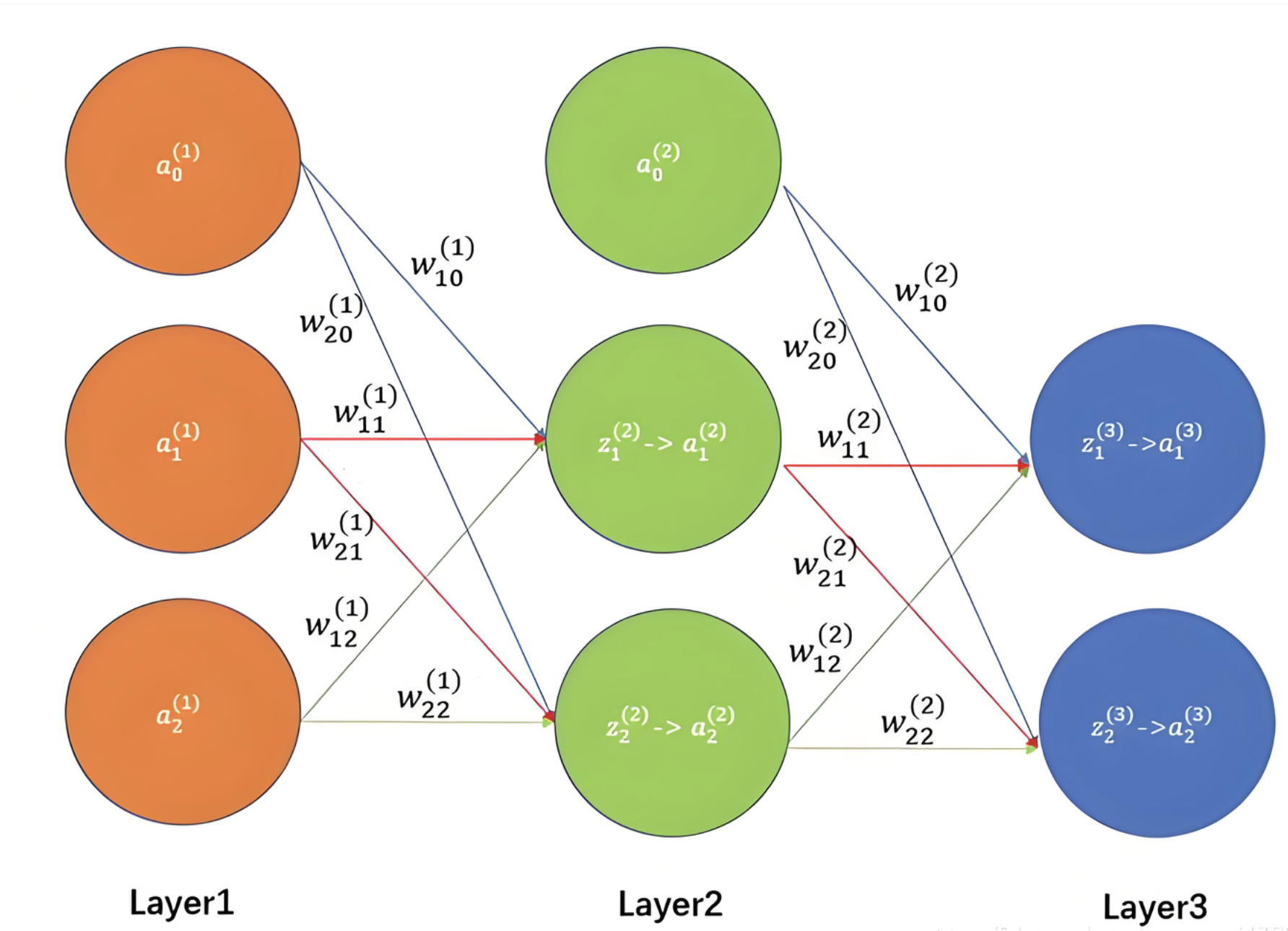
很多人第一次接触 Embedding 时,会把它理解成“把 one-hot 降维”。这个理解没错,但只说了一半。Embedding 更重要的能力是:把离散对象放进一个连续向量空间,让模型能够学习它们之间的关系。
Read
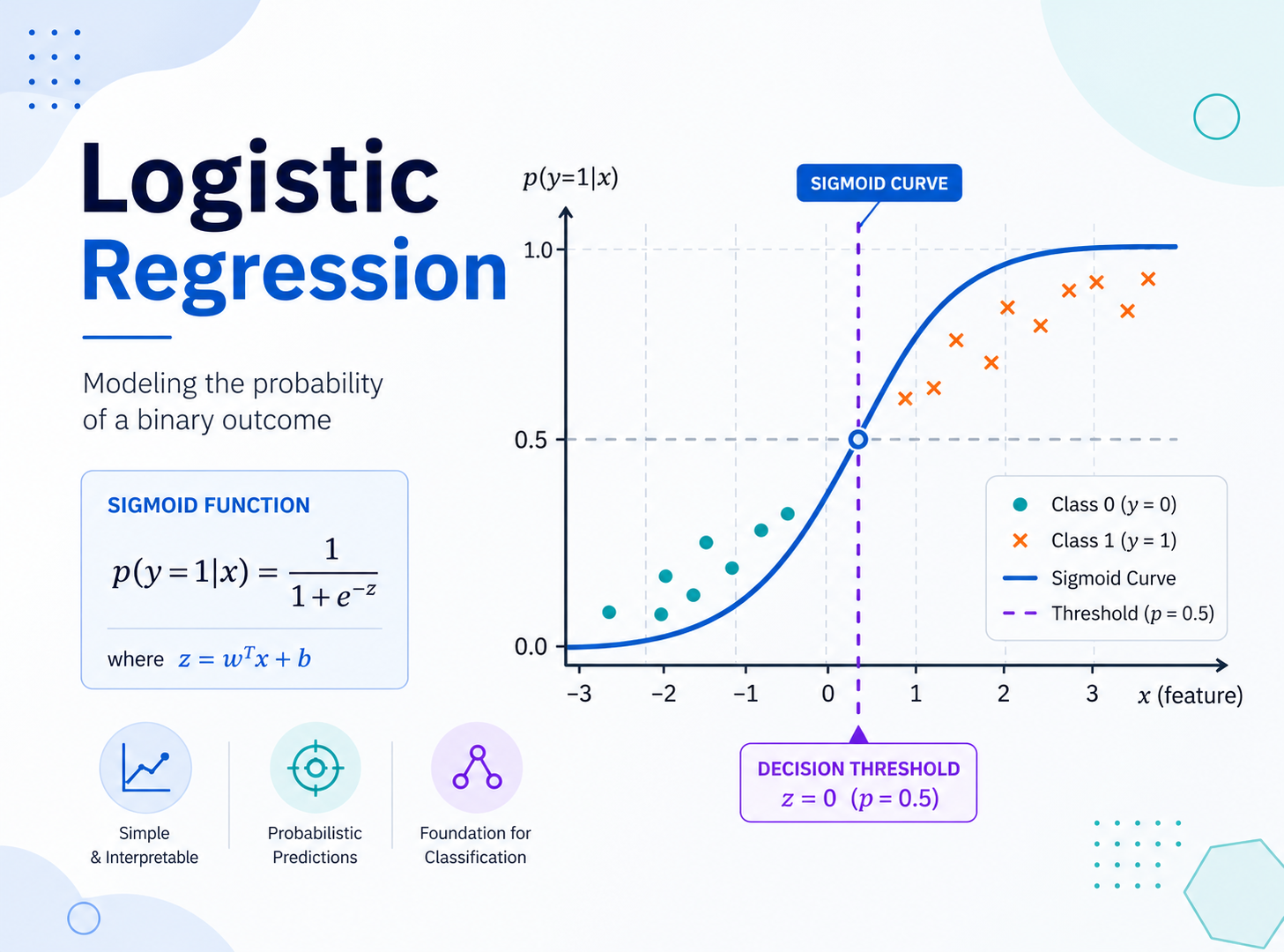
Logistic Regression,中文通常叫逻辑回归。名字里带“回归”,但它最常见的用途其实是分类,尤其是二分类。
Read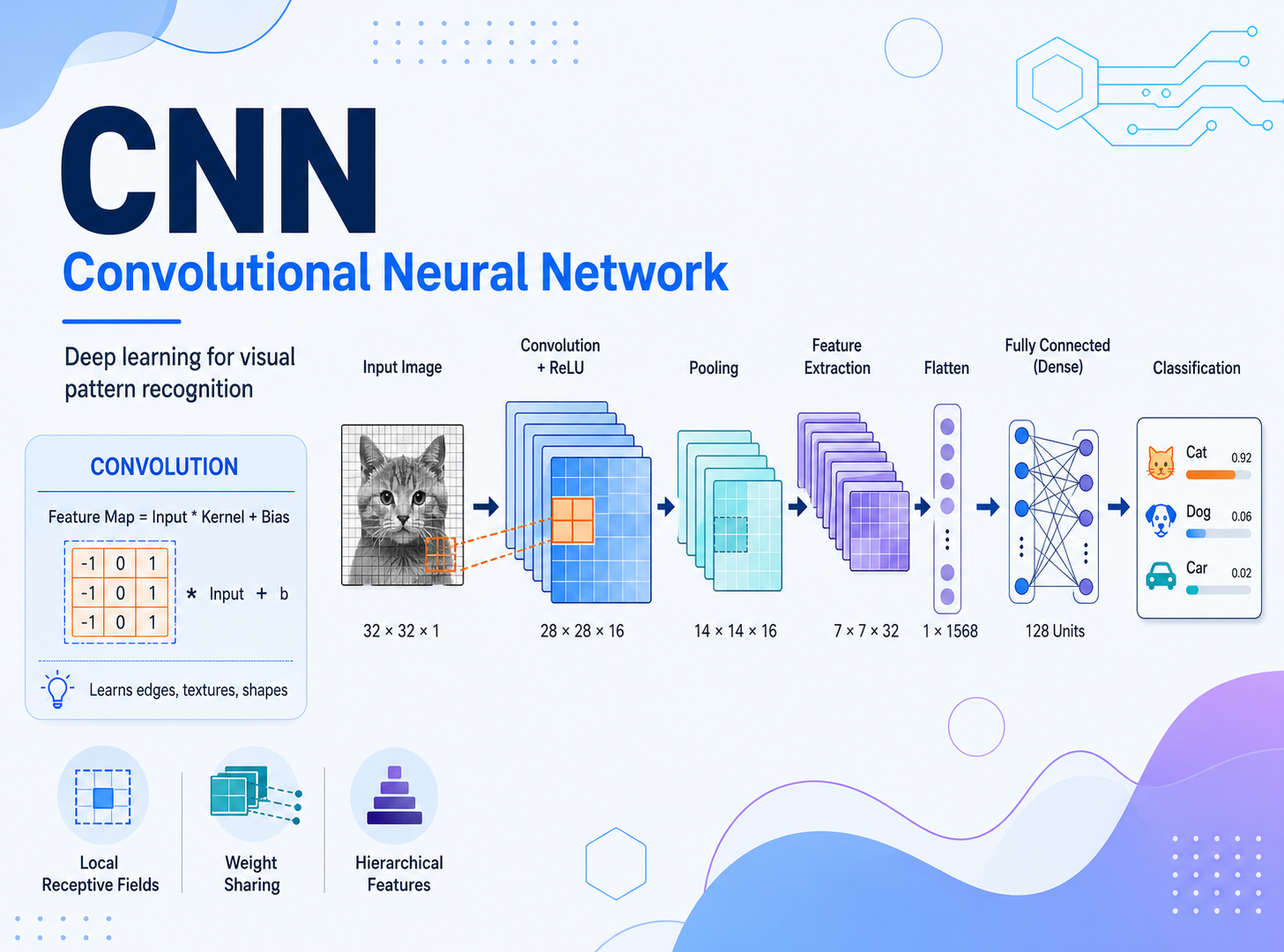
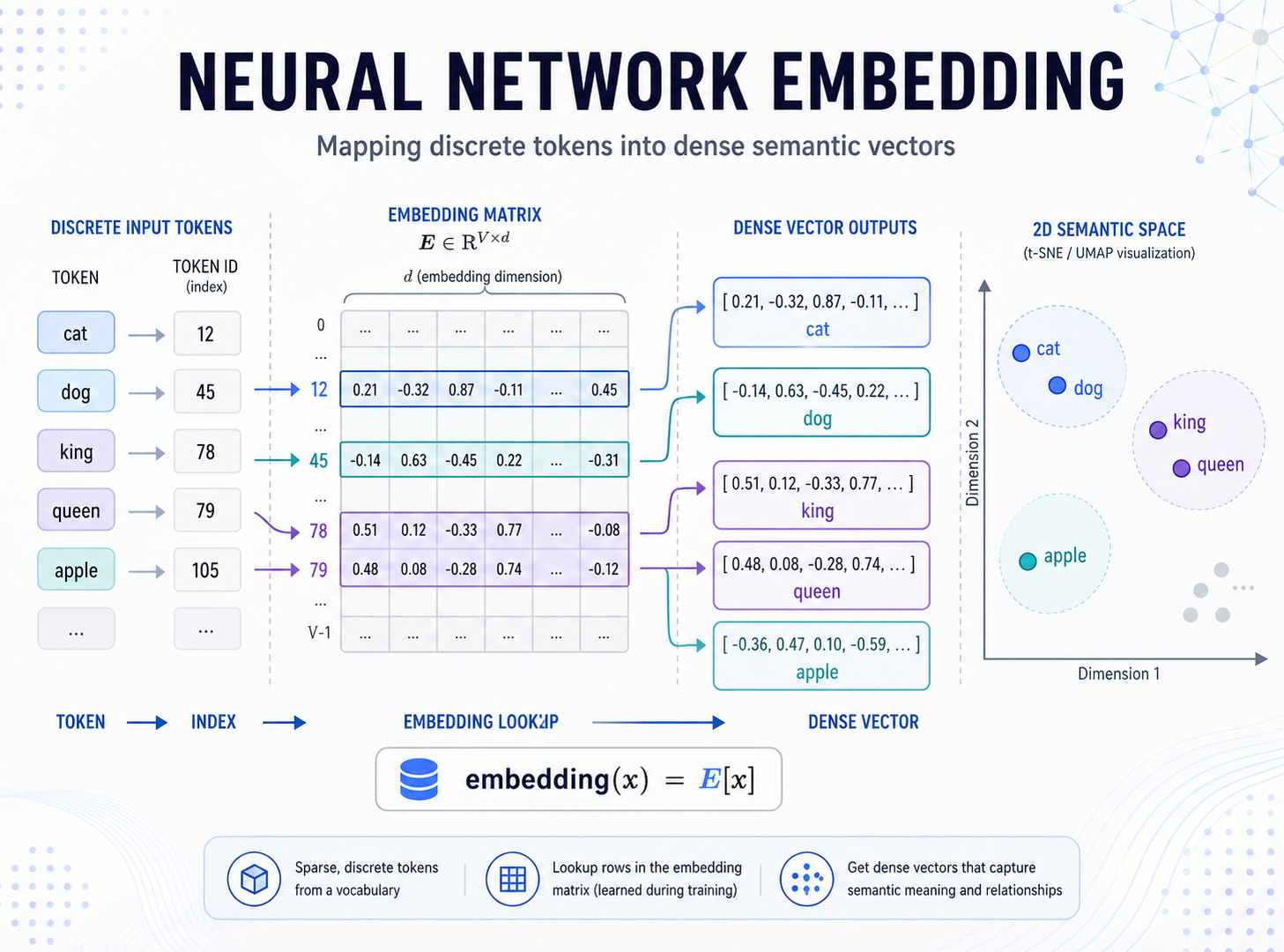
Embedding 是深度学习里非常常见的一层,尤其是在自然语言处理、推荐系统、搜索、广告、用户画像这些场景里,几乎到处都能看到它。
Read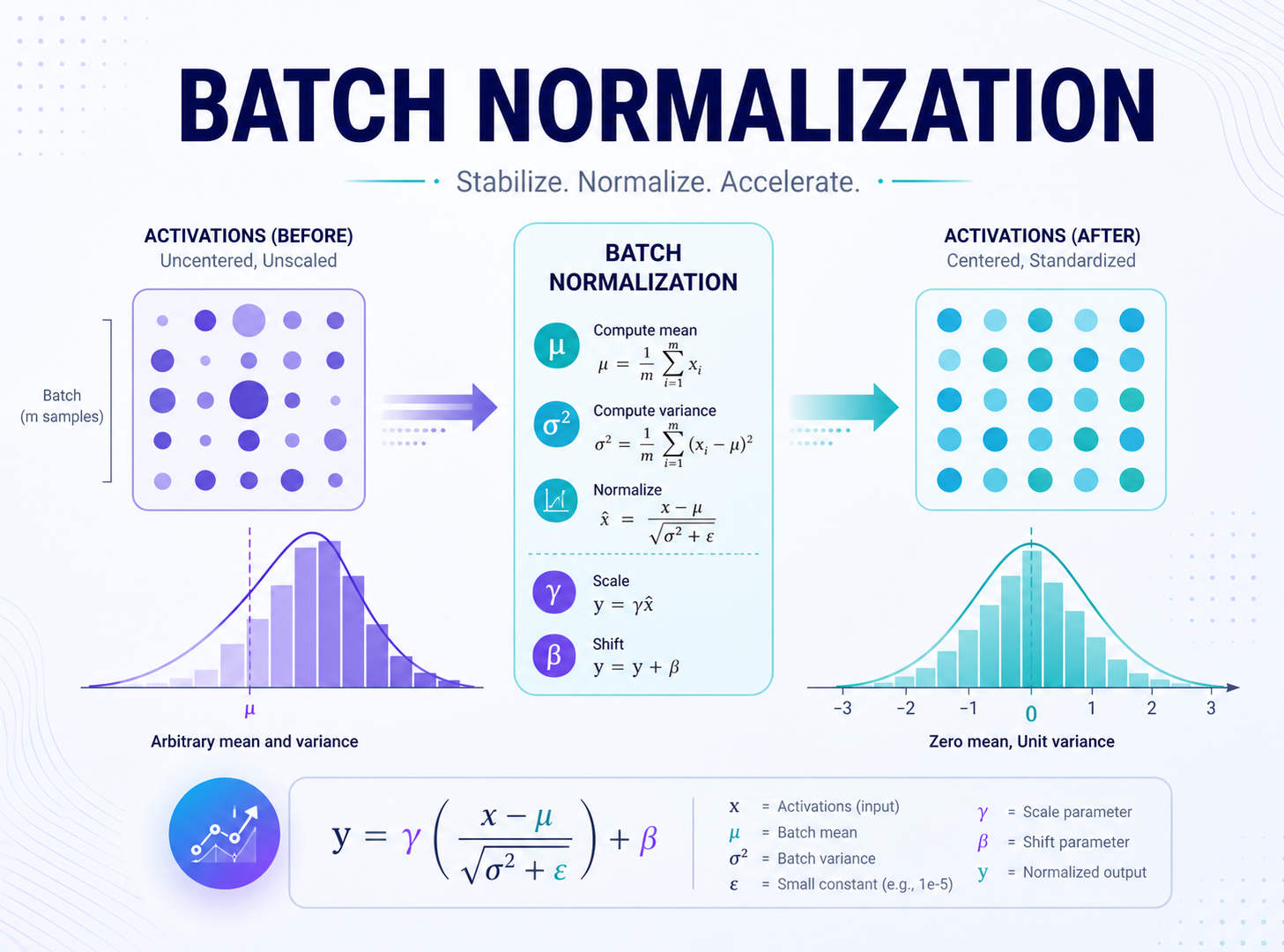
卷积神经网络听起来很硬核,但很多常见组件其实都在解决很朴素的问题:让网络更好训练、让梯度更稳定、让模型别太容易记住训练集。
Read