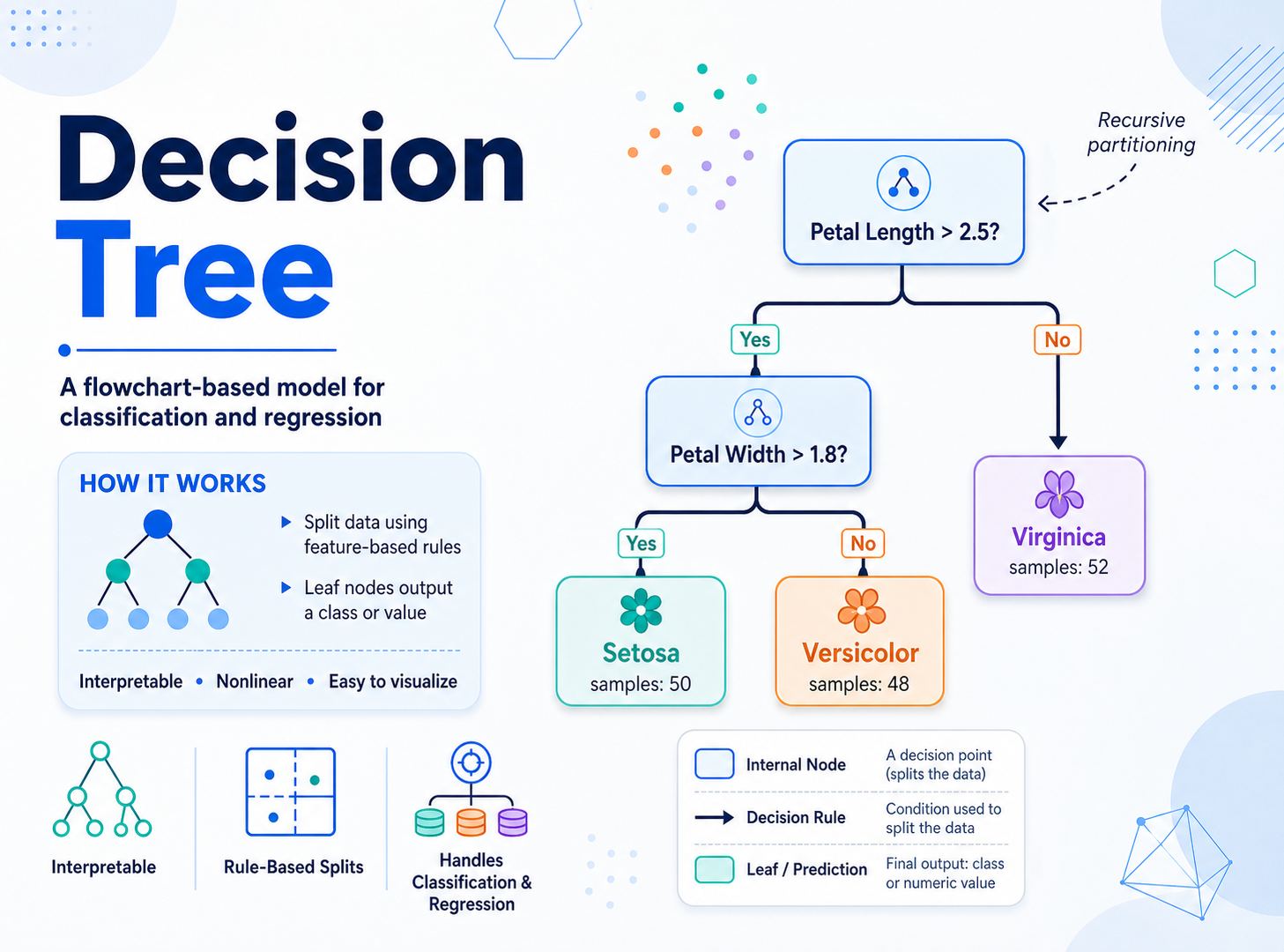
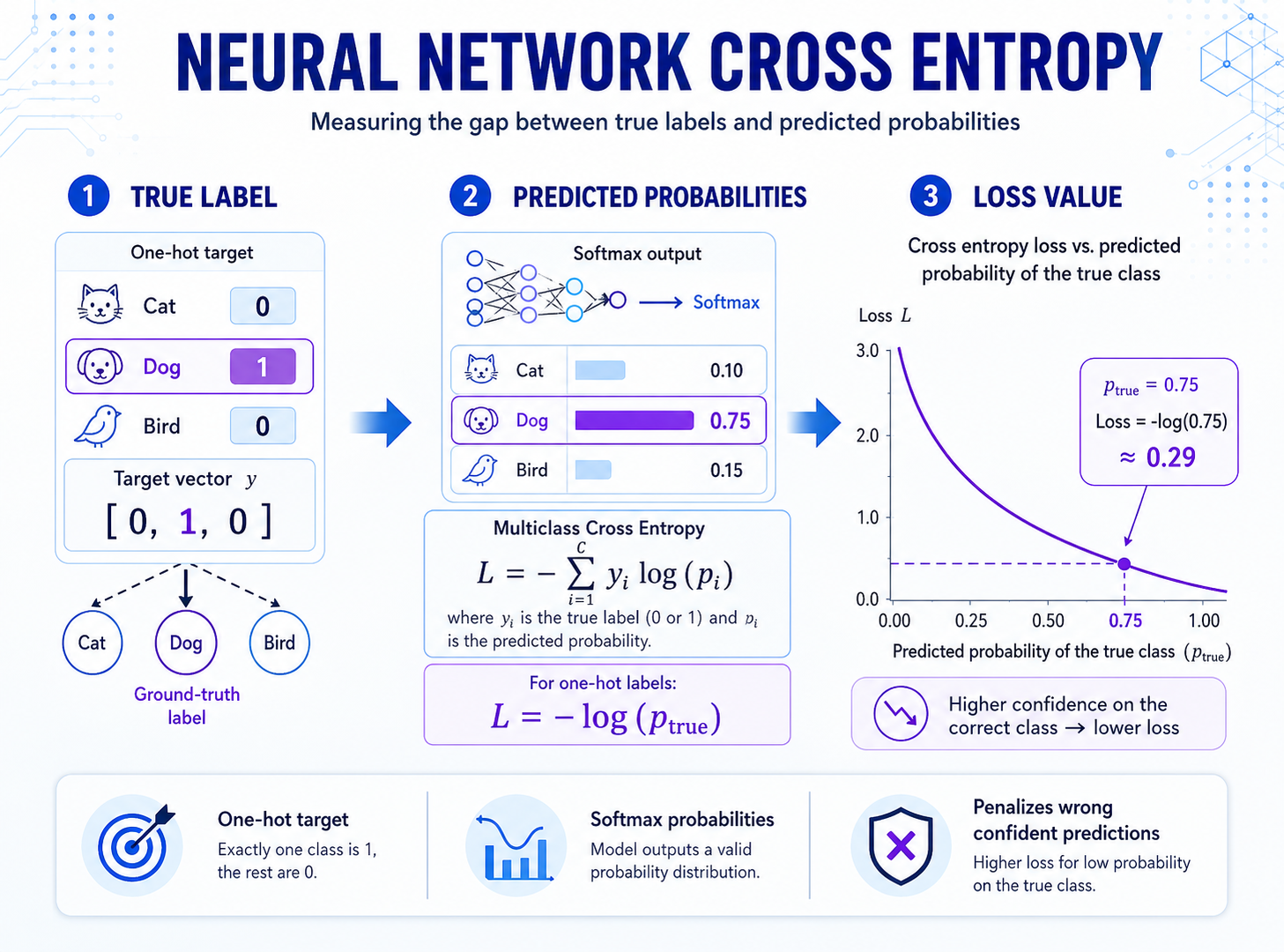
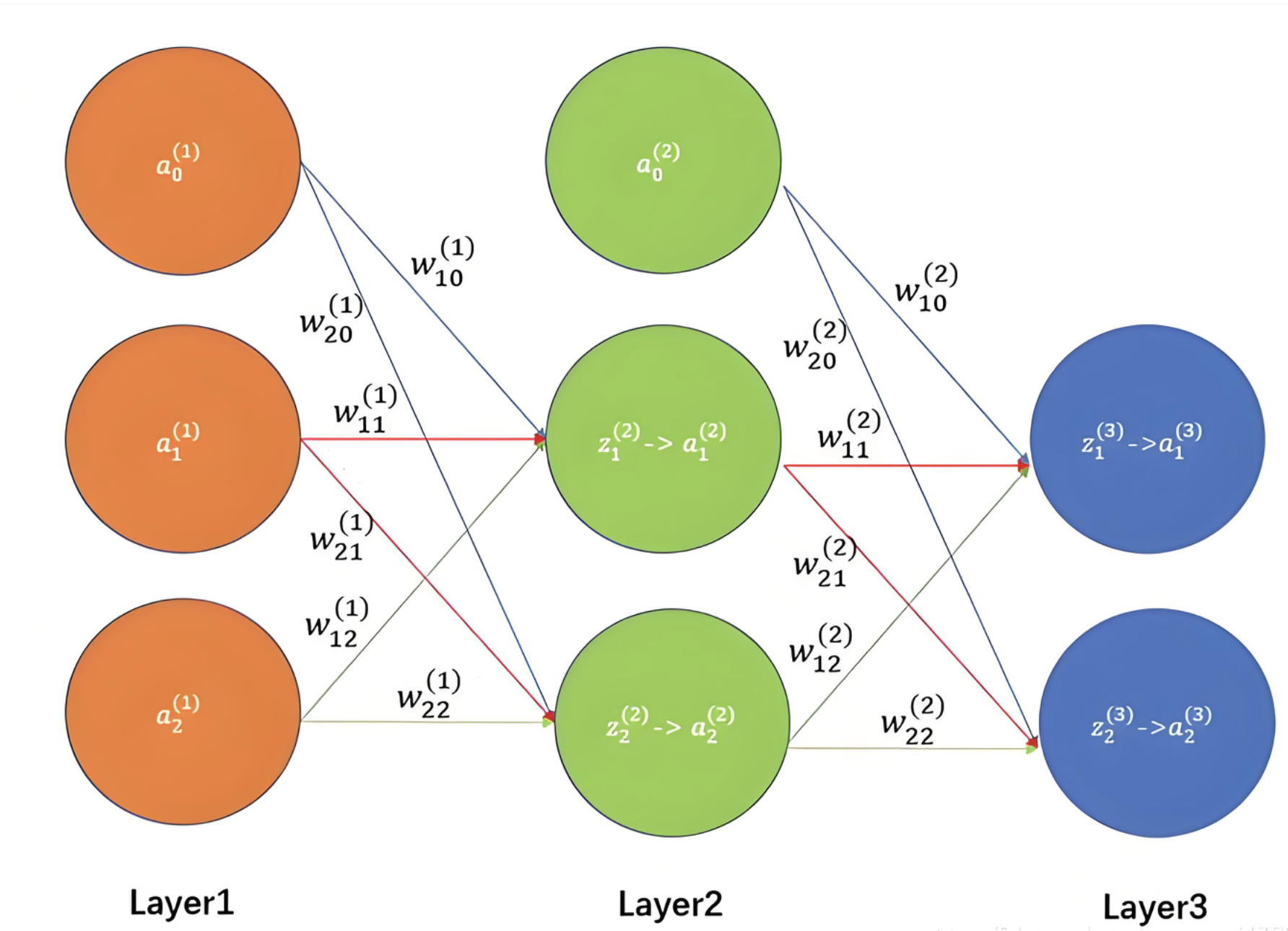
ALL
Writing Index
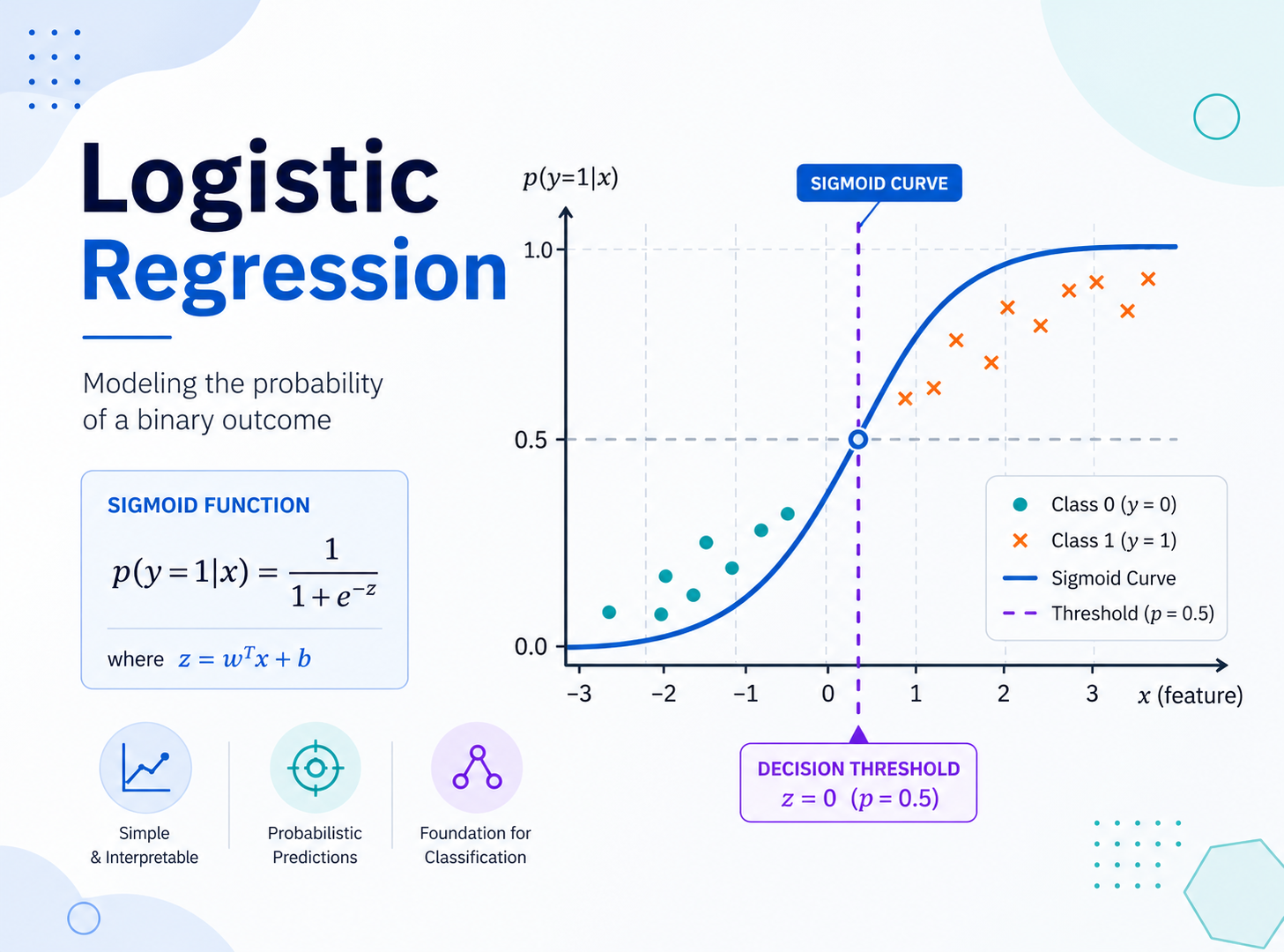
Logistic Regression,中文通常叫逻辑回归。名字里带“回归”,但它最常见的用途其实是分类,尤其是二分类。
Read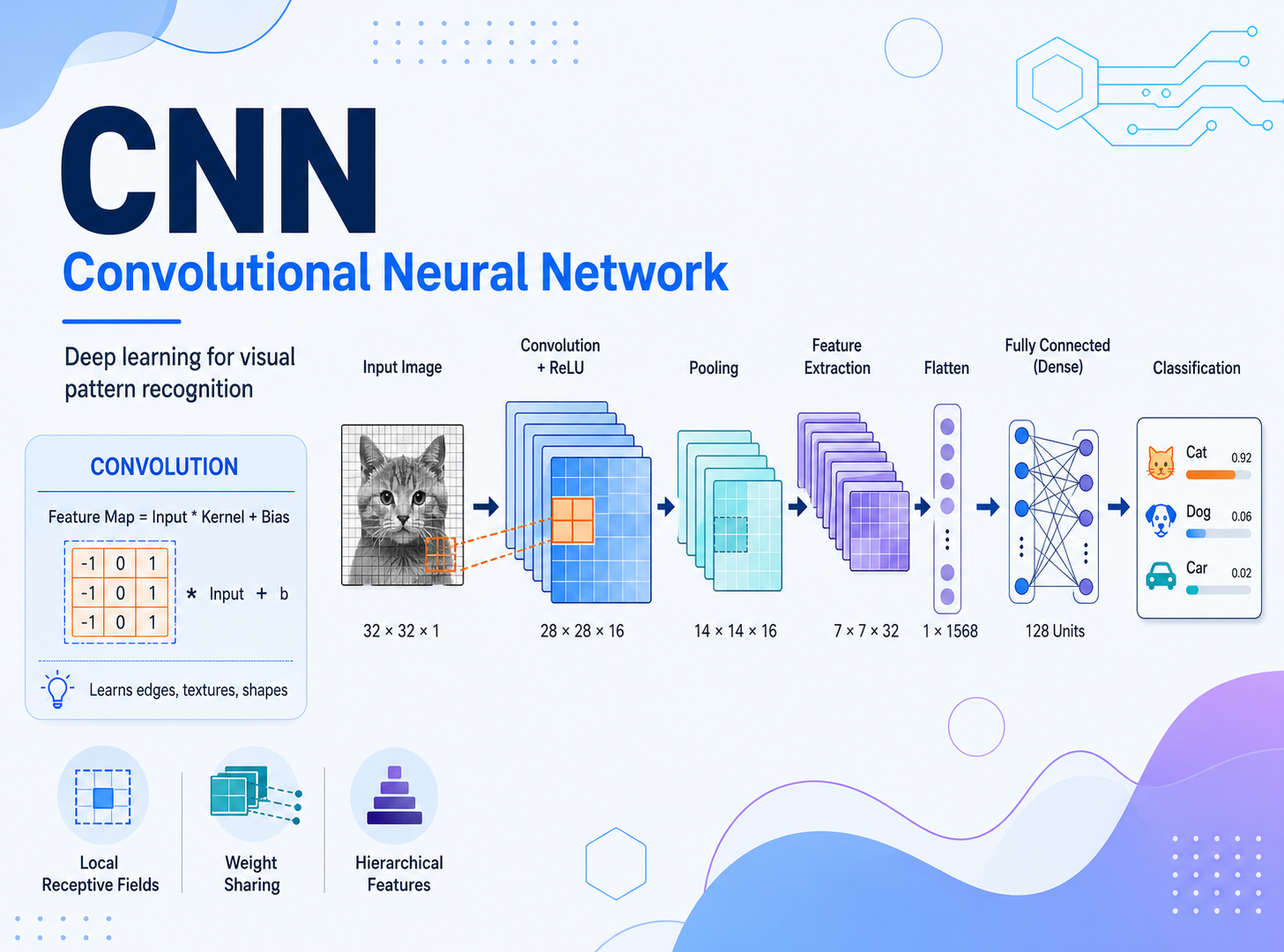
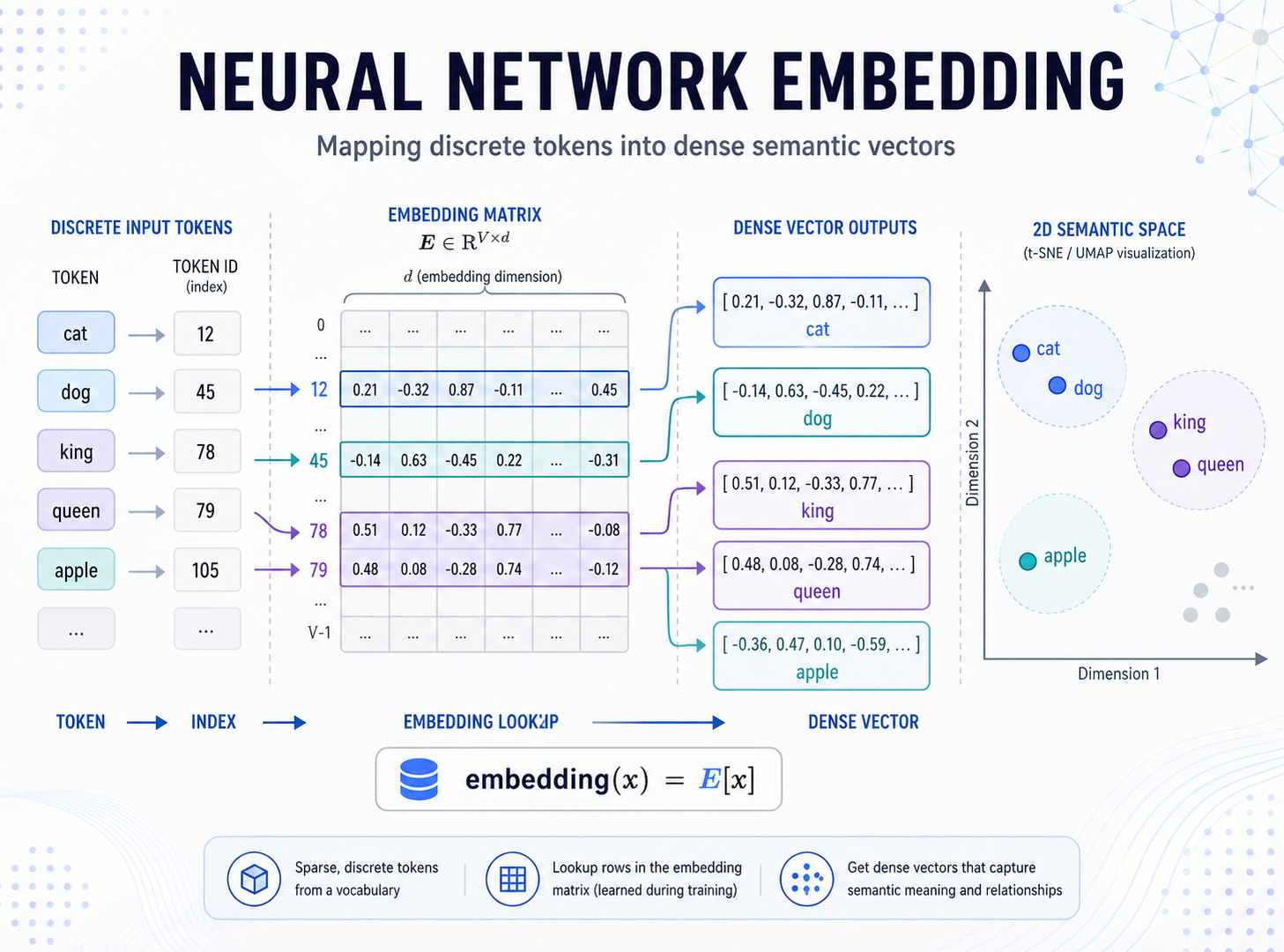
Embedding 是深度学习里非常常见的一层,尤其是在自然语言处理、推荐系统、搜索、广告、用户画像这些场景里,几乎到处都能看到它。
Read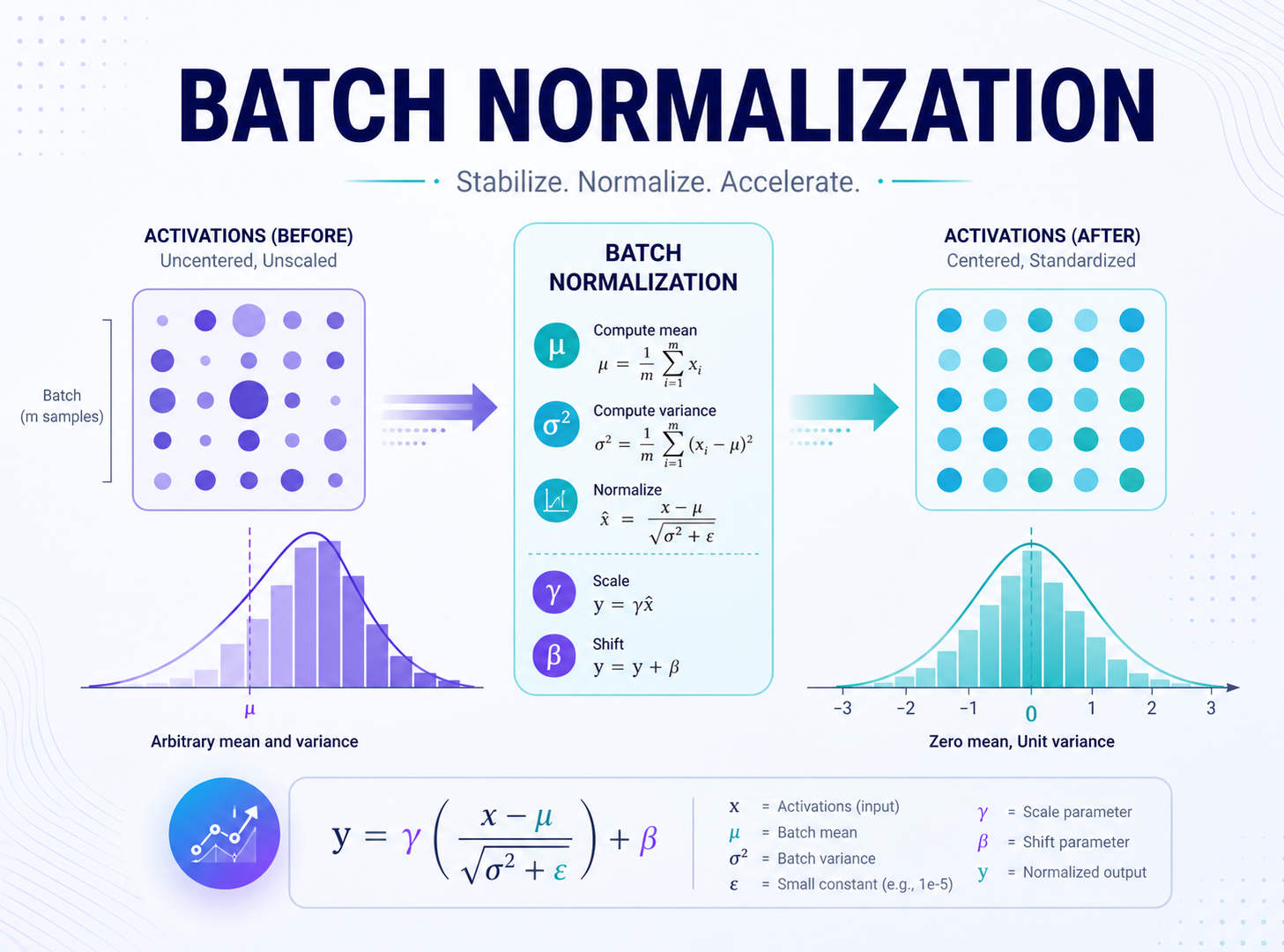
卷积神经网络听起来很硬核,但很多常见组件其实都在解决很朴素的问题:让网络更好训练、让梯度更稳定、让模型别太容易记住训练集。
Read